
Одна из важных составляющих успешных экспериментов в работе над продуктом — отсутствие монополии на формулирование гипотез. Так в создании гипотез, их приоритизации и тестировании участвует вся команда: продакт-менеджеры, аналитики, дизайнеры, UX-исследователи и разработчики.
О том, как благодаря внедрению нового процесса работы с гипотезами для A/B тестирования в (лидер среди приложений в сфере женского здоровья) удалось увеличить долю успешных экспериментов на 30%, рассказывает Head of Analytics Flo Дима Золотухин в своем материале для GoPractice.
Если вы хотите глубже разобраться в том, как создаются, развиваются и масштабируются продукты, пройдите обучение в симуляторах GoPractice.
→ «Симулятор управления продуктом на основе данных» поможет научиться принимать решения с помощью данных и исследований при создании продукта (путь от 0 к 1).
→ «Симулятор управления ростом продукта» поможет найти пути управляемого роста и масштабирования продукта. Вы построите модель роста и составите стратегию развития продукта (путь от 1 к N).
→ «Симулятор SQL для продуктовой аналитики» поможет освоить SQL и применять его для решения продуктовых и маркетинговых задач.
→ «Симулятор управления ML/AI-проектами» научит применять технологии машинного обучения с пользой для бизнеса.
Не знаете с чего начать? Пройдите бесплатный тест для оценки навыков управления продуктом. Вы определите свои сильные стороны и слепые зоны, получите план профессионального развития.
Еще больше ценных материалов и инсайтов — в телеграм-канале .
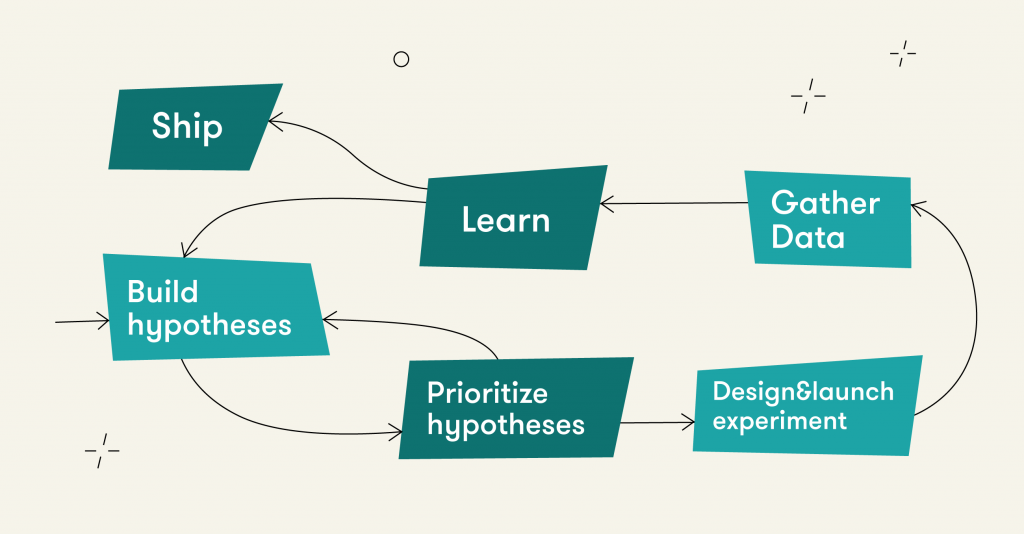
Обратите внимание: этот материал написан в ноябре 2020 года.
Шаблон построения гипотезы и ее компоненты
Гипотеза — утверждение, которое требует доказательства и потенциально может быть проверено с помощью эксперимента.
Гипотеза формулируется в виде: «если мы <описание изменений>, то это улучшит пользовательский опыт <сегмент пользователей> и <метрика> увеличится на <Х>%».
То есть у правильно сформулированной гипотезы есть как минимум четыре обязательных компонента.
- Описание изменений — что конкретно мы хотим изменить?
- Сегмент пользователей — для кого делаем?
- Метрика — как будем измерять успех?
- Масштаб изменения метрики — какое изменение будем считать успехом?
Давайте разберем стандартную гипотезу по компонентам.
Шаблон гипотезы. Описание изменений
Самый удачный вариант для описания изменений — небольшой мокап, на котором любой участник команды быстро поймет, что конкретно для пользователя будет меняться. Это можно сделать как в специальных инструментах вроде Figma (если меняется UI) или Miro (если изменения касаются логики серверной части), так и нарисовав скетч от руки.
Из нашего опыта люди воспринимают и запоминают визуальную информацию намного лучше, чем текст.
Шаблон гипотезы. Сегмент пользователей
На этом этапе нам нужна только примерная оценка сегмента аудитории. Важно, чтобы это был именно определенный сегмент пользователей, обладающий общими задачами и/или паттернами поведения.
Благодаря сегментации аудитории всем участникам команды проще понимать пользователей продукта. Сегментацию вовсе не обязательно (скорее, даже нежелательно) делать при помощи продвинутых ML-методов.
Например, мы в Flo делим пользователей на сегменты в зависимости от цели использования приложения. Цель использования мы уточняем на онбординге. Список сегментов (целей) мы определяли и подтверждали качественными исследованиями исходя из того, какую основную цель могут ставить перед собой пользователи в приложении.
Шаблон гипотезы. Ключевая метрика и иерархия метрик
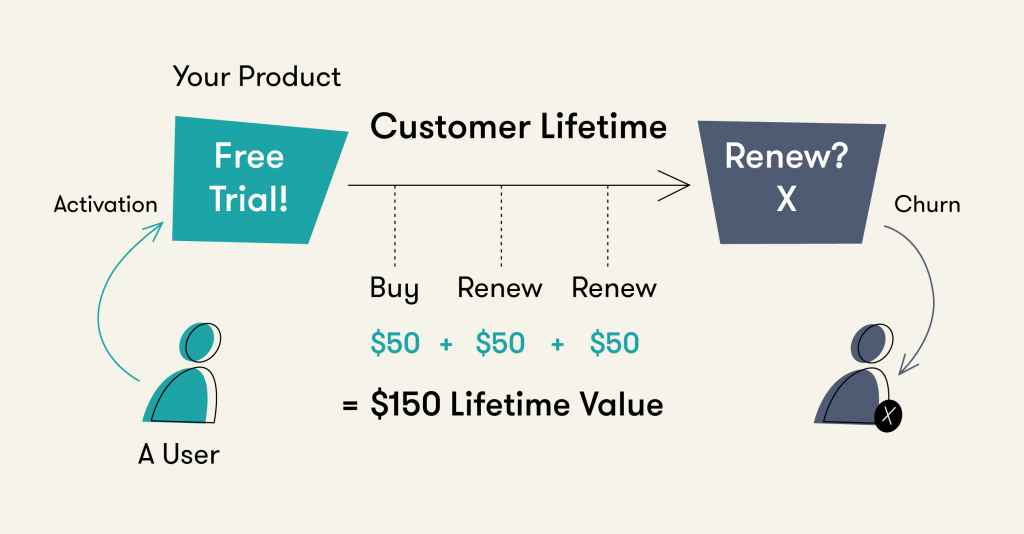
В Flo мы опираемся на OKR компании при выборе метрик. KR на уровне компании представляют собой микс бизнесовых (монетизационных) и UX-метрик. Так мы изначально понимаем, какие именно показатели хотим улучшить. Это позволяет ограничить набор гипотез и выбирать только релевантные идеи.
Продуктовая команда не всегда может непосредственно и значимо влиять на верхнеуровневые бизнес-метрики. Кроме того, часто они составные. Пример — LTV пользователя, который в подписочных приложениях состоит из сложной воронки: конверсия в триальную подписку, далее конверсия в платеж и последующие конверсии в продление.
Поэтому мы много инвестируем в единую иерархию метрик в компании, которая поможет:
- разложить составные бизнес-метрики (например, LTV) на компоненты;
- связать компоненты бизнес-метрик с продуктовыми;
- выстроить несколько уровней продуктовых метрик в зависимости от их чувствительности.
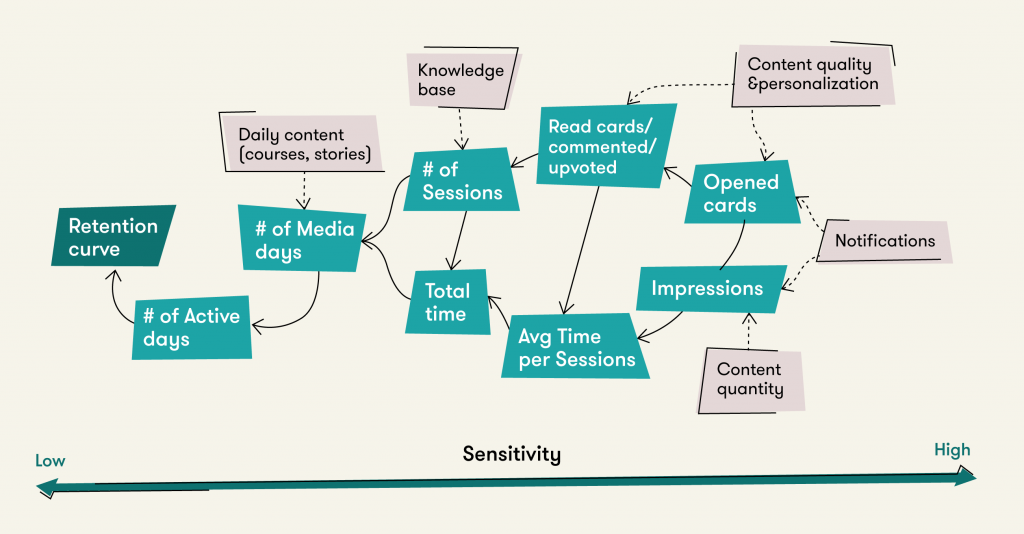
Такая систематизация сильно упрощает выбор метрики в команде. Двигаясь по иерархии метрик, участники лучше понимают, на что именно они могут повлиять, как это связано с топлайн метрикой.
Построение иерархии актуально не только для больших и сложных продуктов, но и для более простых. Ведь основная цель этого упражнения для команды — понять, кто и на что она может эффективно влиять.
Шаблон гипотезы. Прокси-метрики для оценки экспериментов
Довольно часто в экспериментах требуется оптимизировать долгосрочную метрику, например, долгосрочный retention, но ждать месяцы или даже годы у команды возможности нет. Измерять эффект быстрее, но с некоторыми погрешностями помогут прокси-метрики.
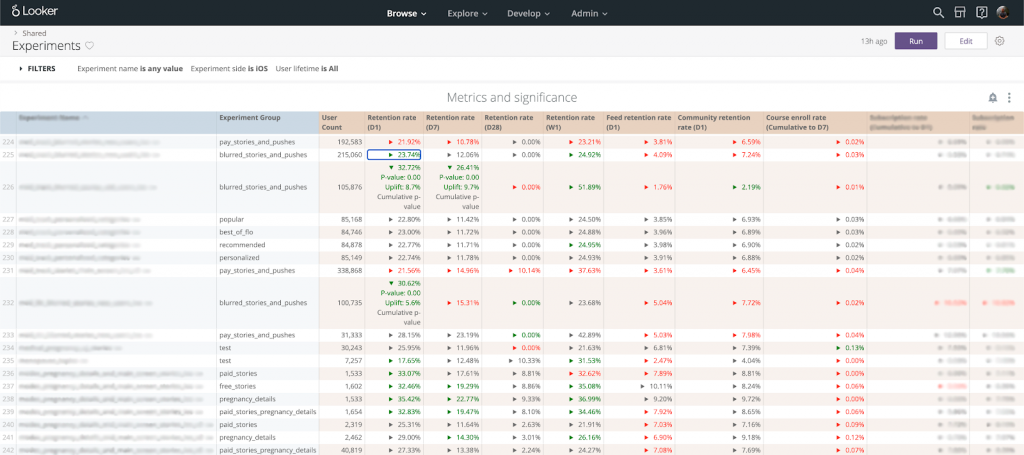
Сходство бинарных метрик можно оценивать с помощью . На иллюстрации видим, что метрика retained М1 (возврат во второй месяц после установки, отсчет с нуля) на 60% сходна с метрикой retained up to D7 (возврат между вторым и восьмым днем после установки). В первом случае нам надо ждать два месяца для того, чтобы получить оценку эффекта, во втором — восемь дней.

Не всегда очевидно, как работать с трейд-оффом между точностью и скоростью расчета. Принимать решение будет проще, если установить внутренний KPI по точности (сходству).
Шаблон гипотезы. Business vs. UX
В некоторых случаях оптимизация бизнес-метрик может вступать в противоречие с User Experience и общей ценностью продукта для пользователей. Например, если делать более агрессивную монетизацию.
Такие кейсы можно контролировать с помощью health-метрик, которые как раз отвечают за UX. Health-метрика, как правило, разнонаправлена с основной метрикой эксперимента (если это бизнес метрика), и главное — ее не «уронить».
Самый популярный пример health-метрики — Retention, но мы используем и другие метрики на разных уровнях иерархии. Например, часто смотрим «активацию» конкретной фичи приложения, чтобы быть уверенными, что изменения ее не обвалили.
Шаблон гипотезы. Масштаб изменения метрики
Мы пришли к одному из самых сложных вопросов — как определить потенциал изменения метрики.
На этапе приоритизации гипотез, как правило, сложно получить супер-достоверную оценку, поэтому надо стараться получить оценку примерную, которая может также быть подтверждена интуицией (об этом чуть позже).
Мы знаем сегмент аудитории, на которую должны повлиять изменения. Но откуда получить информацию об эффекте?
1. «Холодный расчет»
В некоторых случаях масштаб изменений можно просчитать. Например, перед запуском новой фичи можно опросить своих пользователей, насколько они заинтересованы в запуске новой Feature X. Исходя из этого, можно оценить интервал потенциальных конверсий и планируемый эффект.
2. История экспериментов
Историю экспериментов надо хранить как минимум для этого. Находим похожие эксперименты, которые, например, запускались на другой платформе/языке/стране или похожи по теоретическому масштабу изменений. Берем средний эффект. В крайнем случае можем посмотреть вообще все эксперименты с нужной нам метрикой и взять медиану, 75-й перцентиль или максимум изменения в зависимости от вашей уверенности в гипотезе.
3. Рыночное исследование
Иногда оценить эффект от изменения можно по косвенным признакам из рыночного исследования. Как правило, это касается гипотез с рынка, подсмотренных в каком-то виде у конкурентов или просто у других продуктов. В известных сервисах вроде AppAnnie мы можем посмотреть, какой эффект оказало обновление на верхнеуровневые метрики конкурентов. Желательно, чтобы это работало в обе стороны: берете гипотезу/фичу с рынка — обязательно посмотрите на ее влияние в том продукте, где она реализована.
4. Just Noticeable Difference (JND)
Мы можем предлагать что-то суперпрорывное и вообще ничего не понимать с точки зрения эффекта. Рекомендуем определить на каждом уровне иерархии метрик — масштаб изменений, который точно будет заметен на необходимом уровне. Тогда в случае запуска эксперимента вы всегда будете понимать, насколько он успешен.
Приоритизация гипотез для тестирования с помощью ICE
Мы научились формулировать гипотезы, но у нас их много, и нам надо понимать, как находить наиболее перспективные.
Мы пользуемся чек-листом из пяти пунктов, которые позволяют упростить выбор и найти хорошие гипотезы.
Итак, гипотеза хорошая, если:
- потенциально решает реальные проблемы/задачи пользователей;
- имеет обоснования из анализа данных, UX-исследования или исследования рынка;
- связана с долгосрочной продуктовой стратегией;
- приводит к заметному увеличению важных продуктовых метрик в иерархии;
- сложность реализации адекватна потенциальному выигрышу.
Легко заметить, что некоторые пункты чек-листа могут противоречить друг другу и, по сути, являются утопией.
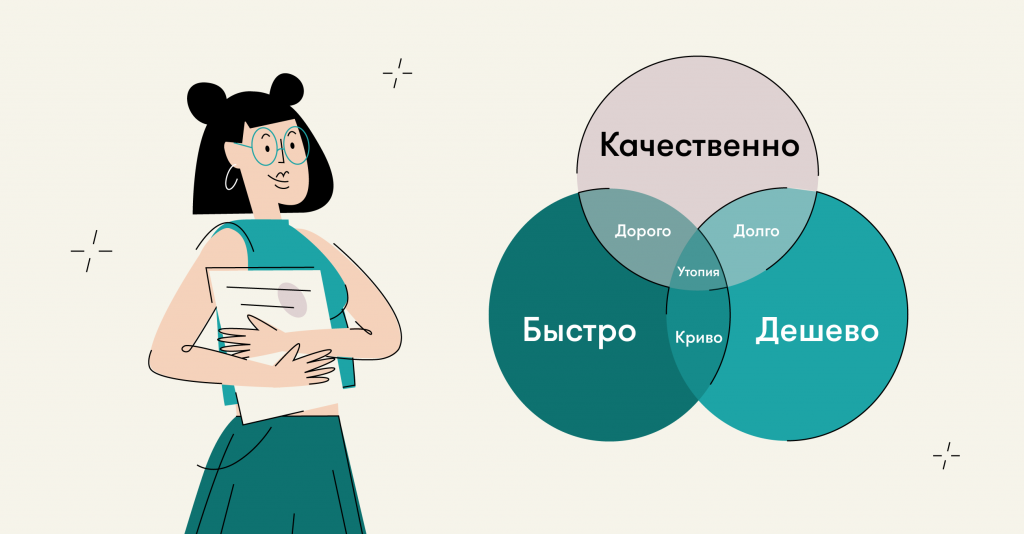
На помощь нам приходит методика приоритизации ICE, которая поможет выстроить бэклог из гипотез.

Чек-лист легко превращается в элементы ICE:
- решает реальные проблемы/задачи пользователей (I);
- имеет подтверждение либо из анализа данных, либо из UX-исследования, либо из исследования рынка (C);
- связана с долгосрочной продуктовой стратегией (I);
- приводит к заметному увеличению метрик (I);
- реализуется достаточно просто (E).
Мы в Flo используем Data Informed ICE: аналитики информируют команду о прогнозном Impact (влиянии изменения), но каждый принимает решение об оценке для ICE лично. Это позволяет привнести элемент продуктовой интуиции в процесс приоритизации и снижает разброс оценок, который бывает при отсутствии бейзлайна.
Запуск экспериментов (A/B тестов)
Получив бэклог из гипотез, мы идем далее по процессу:
- Запускаем эксперименты. О том, как технически у нас реализован эксперимент-сервис, вы можете прочитать в .
- Собираем необходимые данные и анализируем результаты.
- Делаем выводы и принимаем решение о раскатке. Принять решение раскатывать ли тестовую группу на 100% не всегда так просто, как может показаться. Это может быть темой для отдельной статьи. От себя могу только рекомендовать еще до запуска эксперимента определять критерии его успеха — это снимет большую часть сомнений в результатах.
Именно так работают продуктовые команды Flo. Внутри два взаимосвязанных, никогда не заканчивающихся процесса: работа с гипотезами и экспериментирование.
Документирование — важный этап процесса приоритизации и тестирования гипотез
Чтобы работа с гипотезами была действительно системной, надо их сохранять и документировать.
Сейчас приоритизацию мы храним и делаем в Google Sheets. Там же мы храним связь гипотез — сводную таблицу планируемых гипотез, которые влияют на одну Objective. Это не очень удобно. И мы в процессе поиска более удобного инструмента, который позволяет эффективно миксовать OKR, работу с гипотезами и результаты экспериментов.
С похожими проблемами столкнулись ребята из соседней статьи и разработали свой инструмент.
Результаты внедрения процесса работы с гипотезами
Мы работаем по описанному процессу уже несколько кварталов и можем отметить:
- большую вовлеченность и заинтересованность членов команд в процесс планирования, разработки и анализа;
- на 30% больше успешных экспериментов;
- ускорение экспериментов, которые влияют на долгосрочные метрики, за счет использования прокси-метрик.
Сформулировать продуктовую гипотезу правильно не так уж просто, и приоритизация не дается с первого раза. Но если этот процесс настроить и правильно запустить, то скорость и качество развития вашего продукта значительно улучшатся за счет осознанности и эффективной командной работы.
Об авторе
Дима Золотухин, Head of Analytics в компании Flo. Занимается дата-аналитикой 8 лет, с 2017 года — в продуктовых компаниях.
Контакты: .
Если вы хотите глубже разобраться в том, как создаются, развиваются и масштабируются продукты, пройдите обучение в симуляторах GoPractice.
→ «Симулятор управления продуктом на основе данных» поможет научиться принимать решения с помощью данных и исследований при создании продукта (путь от 0 к 1).
→ «Симулятор управления ростом продукта» поможет найти пути управляемого роста и масштабирования продукта. Вы построите модель роста и составите стратегию развития продукта (путь от 1 к N).
→ «Симулятор SQL для продуктовой аналитики» поможет освоить SQL и применять его для решения продуктовых и маркетинговых задач.
→ «Симулятор управления ML/AI-проектами» научит применять технологии машинного обучения с пользой для бизнеса.
Не знаете с чего начать? Пройдите бесплатный тест для оценки навыков управления продуктом. Вы определите свои сильные стороны и слепые зоны, получите план профессионального развития.
Еще больше ценных материалов и инсайтов — в телеграм-канале .