
На рынке генеративного AI произошел новый важный сдвиг, ознаменованный выходом модели o1 от OpenAI. Эта модель отличается возможностью «мышления» в процессе генерации ответа. Подобные модели, в отличие от предыдущих поколений, способны решать более трудные проблемы в области науки, программирования и математики.
В авторы из Sequoia Capital анализируют, как эти фундаментальные изменения в принципах работы моделей генеративного AI отразятся на рынке и что это значит для стартапов и инвесторов. Команда GoPractice подготовила его адаптированный перевод.
***
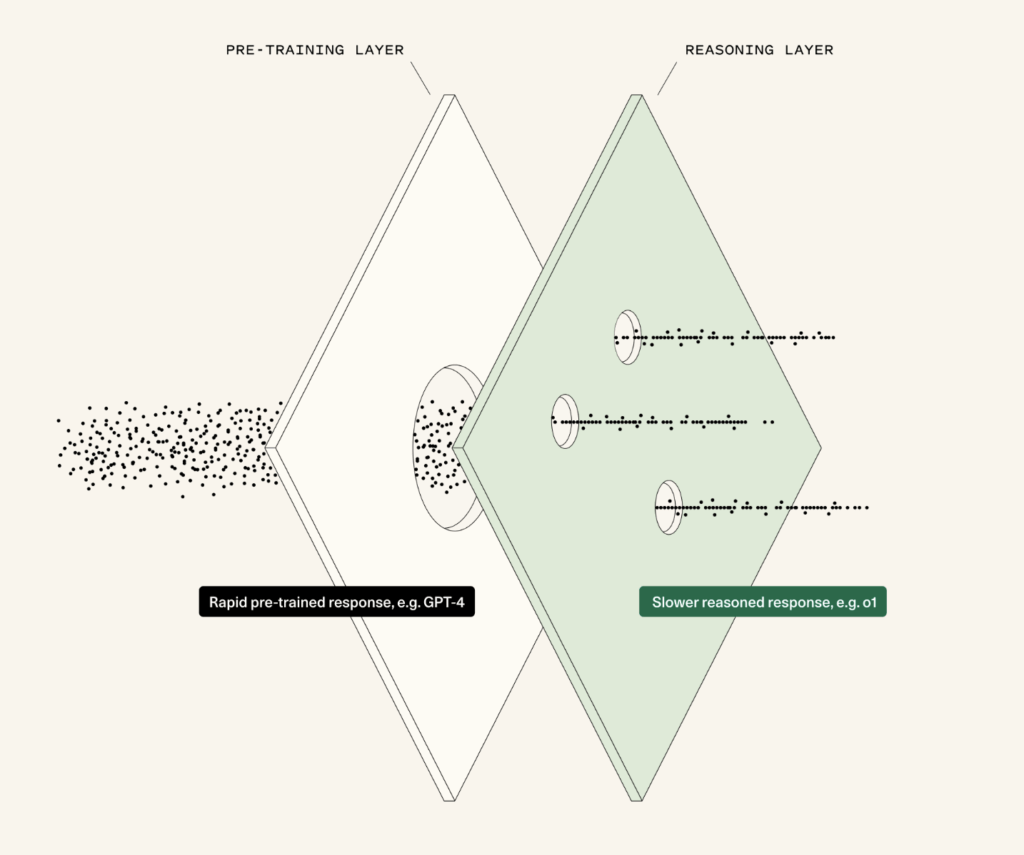
Два года спустя после начала революции в области генеративного AI ее развитие постепенно переходит от «быстрого мышления» — быстрых ответов на основе предварительно обученных моделей — к «медленному мышлению» в процессе генерации ответа. Эта эволюция открывает возможности для нового поколения приложений — AI-агентов.
Во вторую годовщину нашего эссе «» экосистема AI выглядит совершенно иначе, и мы готовы поделиться прогнозами на будущее.
Sequoia Capital — американская венчурная фирма, специализирующаяся на инвестициях в технологические компании. Основана в 1972 году. По данным на 2022 год, под управлением фирмы находятся активы на $85 миллиардов.
На разных этапах Sequoia Capital инвестировала в Apple, Cisco, Google, Airbnb, Instagram** и множество других успешных компаний.
Базовый уровень рынка генеративного AI стабилизируется, формируя равновесие между ключевыми крупными игроками и альянсами, такими как Microsoft/OpenAI, AWS/Anthropic, Meta* и Google/DeepMind. На поле остаются только крупные участники с мощными экономиками и доступом к огромным капиталам. Хотя борьба далеко не окончена (и ), структура рынка становится более устойчивой, и очевидно, что применение больших языковых моделей будет становиться все более дешевым и доступными.
Для больших языковых моделей (LLM) появляется новый рубеж. Фокус смещается на разработку и масштабирование «мышления» (reasoning, то есть технических компонентов, выполняющих функцию, которую можно сравнить с мышлением естественного интеллекта), где приоритетом становится «мышление системы 2». Вдохновленные моделями вроде AlphaGo, эти слои направлены на оснащение систем AI способностью к осознанным рассуждениям, решению задач и когнитивным операциям в процессе генерации ответа.
Что все это означает для основателей стартапов в области AI? Какие выводы из этого могут сделать устоявшиеся софтверные компании? И где мы как инвесторы видим наибольший потенциал для получения доходов от генеративного AI?
Мы рассмотрим, как консолидация foundational моделей подготовила почву для гонки по масштабированию возможностей сложного «мышления» и AI-агентов, а также обсудим новое поколение прорывных приложений.
Strawberry Fields Forever
Самое важное обновление среди моделей 2024 года осуществила OpenAI. Компания выпустила модель o1, также известную как Q* и Strawberry. Это не просто подтверждение лидерства OpenAI в рейтингах качества моделей, но и заметное изменение устоявшейся архитектуры. Более того, это первый пример модели с возможностями «мышления», достигнутыми за счет вычислений в процессе генерации ответа.
Что это значит? Предварительно обученные модели выполняют предсказание следующего токена на основе огромного объема данных. Они опираются на вычисления во время обучения («training-time compute»). Масштаб моделей приводит к возникновению базовых способностей «мышления», но эти способности сильно ограничены. Но что если научить модель самому процессу рассуждения? Именно это и реализовано в Strawberry. Когда мы говорим о мышлении в процессе генерации ответа (“inference-time compute”), мы имеем в виду, что модель «берет паузу и обдумывает» свой ответ, прежде чем его дать. Это требует большего объема вычислений на этапе генерации ответа. Эта фаза «паузы и обдумывания» и есть аналог процесса мышления.
Курс «AI/ML-симулятор для продакт-менеджеров» в группе с ментором:
🔹 Научитесь видеть возможности для применения AI/ML в вашей текущей роли
🔹 Запустите собственный продукт с AI/ML→ ←
AlphaGo и большие языковые модели (LLMs)
Что делает модель, когда она «берет паузу и думает»?
Давайте сначала перенесемся в март 2016 года в Сеул. Здесь случился один из самых значимых моментов в истории deep learning: матч AlphaGo против легендарного мастера игры в го Ли Седоля. Это был не просто матч «AI против человека». В этот момент мир увидел, что AI способен на большее, чем просто воспроизведение примеров, на которых происходило обучение.
Чем AlphaGo отличался от предыдущих игровых AI-систем, таких как Deep Blue? Как и большие языковые модели (LLMs), AlphaGo сначала был предварительно обучен на данных, чтобы подражать человеческим экспертам, используя базу из примерно 30 миллионов ходов из предыдущих игр и собственных партий. Но вместо того чтобы выдавать мгновенный ответ, полученный из предварительно обученной модели, AlphaGo останавливался и обдумывал. На этапе вывода модель запускала поиск или симуляцию широкого диапазона потенциальных будущих сценариев, оценивая их и выбирая тот, который имел наивысшее ожидаемое значение. Чем больше времени на размышления предоставлялось AlphaGo, тем лучше он играл. Без «обдумывания» модель не могла бы победить лучших игроков. Но по мере увеличения времени на генерацию ответа AlphaGo становился все сильнее, пока не превзошел даже лучших гроссмейстеров.
Теперь вернемся к LLM. Почему нельзя просто перенести подход AlphaGo в контекст LLM? Сложность заключается в построении целевой функции — функции, по которой оцениваются ответы модели. В игре го все довольно очевидно: можно смоделировать игру до конца, выяснить, кто выиграл, и вычислить ожидаемую оценку следующего хода. В программировании это тоже относительно просто: можно протестировать код и увидеть, работает он или нет. Но как оценить первый черновик эссе? Или маршрут путешествия? Или краткое содержание ключевых пунктов длинного документа? Это делает рассуждения сложными для текущих методов и объясняет, почему Strawberry сильна в областях, близких к логике (например, программирование, математика, науки), но менее эффективна в более открытых и неструктурированных задачах (например, написание текстов).
Хотя технические детали реализации Strawberry держат в секрете, ключевые идеи включают обучение с подкреплением на основе цепочек рассуждений, создаваемых моделью. Анализ этих цепочек показывает, что происходит нечто фундаментальное и захватывающее — нечто, действительно напоминающее человеческое мышление и рассуждение. Например, o1 демонстрирует способность возвращаться назад, если «застревает». Эта особенность проявляется при увеличении времени на генерацию ответа. Модель также способна подходить к проблемам «по-человечески» (например, визуализировать точки на сфере для решения задачи по геометрии) и находить новые способы решения задач (например, решать задачи из соревнований по программированию способами, которые не используются людьми).
Кроме того, появляются новые идеи для дальнейшего улучшения вычислений на этапе генерации ответа. Исследовательские группы активно работают над улучшением способностей модели к «мышлению». Другими словами, deep reinforcement learning (глубокое обучение с подкреплением) снова в моде.
Мышление Системы 1 vs мышление Системы 2
Переход от предварительно обученных «инстинктивных» ответов («Система 1») к более глубокому, обдуманному рассуждению («Система 2») — это следующий рубеж для AI. Моделям недостаточно просто обладать знаниями: они должны уметь делать паузы, оценивать ситуацию и «рассуждать» в режиме реального времени.
Представьте, что предварительное обучение — это уровень Системы 1. Независимо от того, обучена ли модель на миллионах ходов в го (как AlphaGo) или на петабайтах текстов из интернета (как большие языковые модели, LLM), ее задача — воспроизводить примеры из своего обучающего датасета, будь то игра или язык. Но подражание, каким бы мощным оно ни было, не является истинным рассуждением. Оно не может справиться с новыми сложными ситуациями, особенно с теми, которые выходят за пределы обучающей выборки.
И здесь на сцену выходит мышление Системы 2, которое стало фокусом последних исследований в области AI. Когда модель «берет паузу, чтобы подумать», она не просто воспроизводит запомненные шаблоны или выдает прогнозы на основе прошлых данных. Она создает диапазон возможных решений, оценивает потенциальные результаты и принимает решение на основе их анализа.
Для многих задач Система 1 более чем достаточна. Как отметил Ноам Браун в последнем эпизоде подкаста , долго размышлять над вопросом о столице Бутана бесполезно: вы либо знаете ответ, либо нет. Здесь идеально работает быстрый, шаблонный ответ.
Но когда речь заходит о более сложных проблемах — таких как прорывы в математике или биологии — быстрые, интуитивные ответы не срабатывают. Эти проблемы требуют глубокого анализа, творческого подхода к решению и — что самое важное — времени. То же самое относится и к AI. Чтобы справляться с наиболее сложными и значимыми задачами, AI должен выйти за пределы быстрых, шаблонных ответов и научиться тратить время на формирование обдуманных рассуждений.
Гонка за мышлением на этапе генерации ответа началась
Главный вывод из материалов OpenAI заключается в том, что существует еще один закон масштабирования (scaling law).
Предварительное обучение больших языковых моделей (LLMs) следует хорошо известному : чем больше вычислительных ресурсов и данных используется для предварительного обучения модели, тем лучше она работает.
Статья OpenAI об o1 открывает совершенно новую плоскость масштабирования вычислений: чем больше вычислительных ресурсов предоставляется модели на этапе генерации ответа (inference-time, test-time), тем лучше она рассуждает.
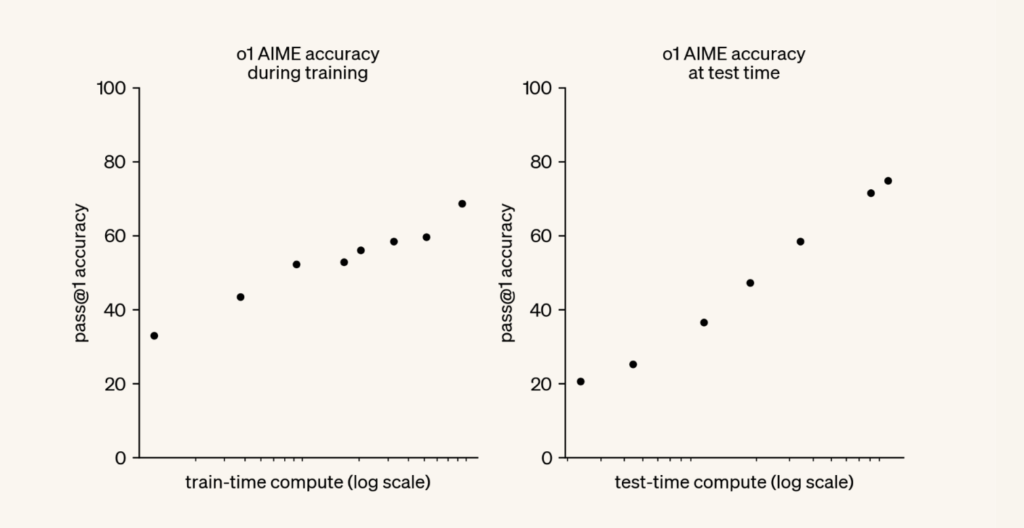
Источник: OpenAI o1 technical
Что произойдет, если модель сможет размышлять часами? Днями? Десятилетиями? Решим ли мы гипотезу Римана? Ответим ли на последний вопрос Азимова?
Этот сдвиг перенесет нас из мира массивных кластеров для предварительного обучения в облака генерации ответа — среды, которые могут динамически масштабировать вычислительные ресурсы в зависимости от сложности задачи.
Одна модель, чтобы править всеми?
Что произойдет, если OpenAI, Anthropic, Google и Meta* продолжат масштабировать свои слои мышления моделей и разрабатывать все более мощные модели для логического мышления? Сможем ли мы получить одну «модель, которая будет править всеми»?
Одна из гипотез на заре рынка генеративного AI заключалась в том, что одна компания, создающая модель, станет настолько могущественной и универсальной, что он вытеснит все другие аналогичные продукты. Однако на данный момент это предсказание оказалось неверным по двум причинам.
Во-первых, на уровне моделей существует значительная конкуренция, и участники рынка постоянно обгоняют друг друга в достижении передового уровня возможностей (SOTA). Возможно, кто-то сумеет разработать механизм непрерывного самоулучшения с использованием широкого спектра самостоятельных симуляций и добиться «взлета», но пока мы не видим этому подтверждений. Наоборот, уровень конкуренции на уровне моделей остается высоким: цена за токен в GPT-4 снизилась на 98% с последнего OpenAI developer day.
Во-вторых, модели в основном не смогли закрепиться на уровне приложений как революционные продукты, за исключением ChatGPT. Реальный мир слишком сложен. Исследователи обычно не стремятся вникать в детали и разрабатывать сквозные рабочие процессы для каждой функции в каждой возможной отрасли. Экономически оправданно, что они останавливаются на уровне API, оставляя разработчикам задачу решать сложные проблемы реального мира. Это хорошие новости для уровня приложений.
Сложности реального мира: когнитивные архитектуры
Подход к планированию и выполнению действий для достижения целей ученого сильно отличается от работы инженера-программиста. Более того, даже среди инженеров-программистов подходы могут различаться в зависимости от компании.
В то время как исследовательские лаборатории продолжают работу над фундаментальными моделями, бизнесам необходимы специализированные прикладные решения для создания полезных AI-агентов. Сложный реальный мир требует использования значительного количества доменно-ориентированной логики, которую пока невозможно эффективно встроить в универсальную модель.
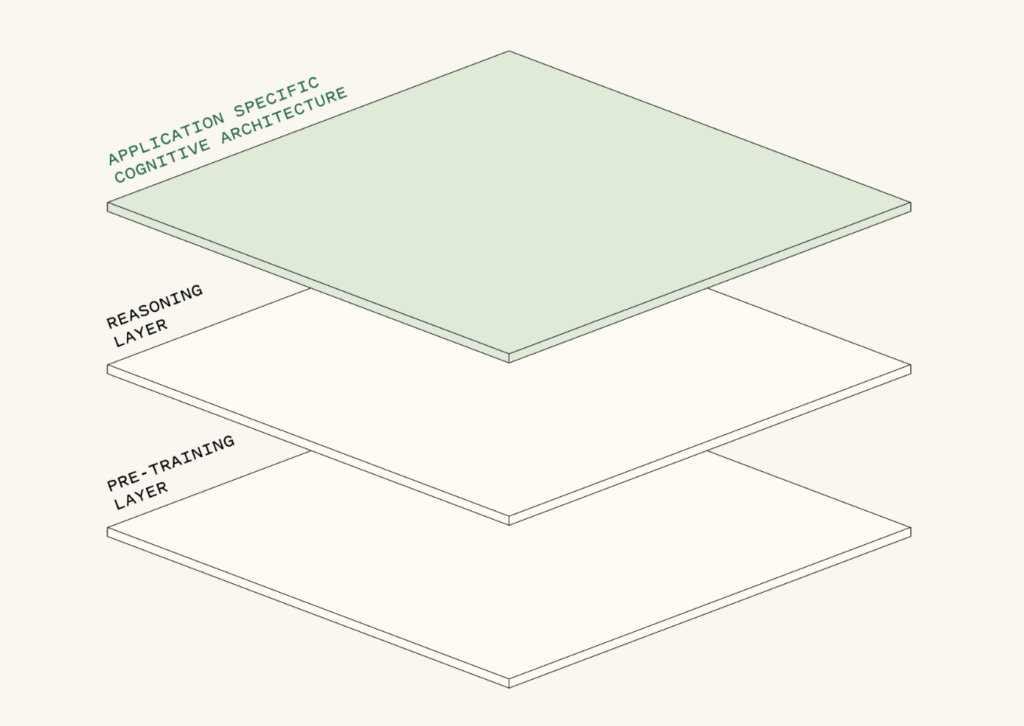
— это способ, которым система обрабатывает входные данные пользователя, взаимодействует с кодом и моделями, чтобы выполнить действия или сгенерировать ответ.
Например, в случае каждый из их продуктов, называемых «дроидами», имеет индивидуальную когнитивную архитектуру, которая имитирует человеческий подход к выполнению определенной задачи — например, ревью кода или написание и выполнение плана миграции для обновления сервиса с одного бэкенда на другой.
Дроид Factory разбивает все зависимости, предлагает соответствующие изменения в коде, добавляет юнит-тесты и привлекает человека для проверки. Затем, после одобрения, он применяет изменения ко всем файлам в тестовой среде и делает merge кода, если все тесты успешно проходят. Точно так же, как это сделал бы человек — выполняя серию отдельных задач, а не предоставляя одно обобщенное решение в виде «черного ящика».
Что происходит с приложениями?
Представьте, что вы хотите создать бизнес в области AI. На каком уровне стека вы сосредоточитесь? Конкурировать в инфраструктуре? Удачи вам обойти NVIDIA и иных ведущих провайдеров. Конкурировать на уровне моделей? Удачи догнать OpenAI и Марка Цукерберга. А как насчет приложений? Удачи в борьбе с корпоративным IT и глобальными системными интеграторами. Ой. Подождите. А это действительно звучит выполнимо!
Фундаментальные модели — это магия, но они также полны сложностей. Большие компании не могут работать с «черными ящиками», галлюцинациями и неуклюжими рабочими процессами. Обычные пользователи, глядя на пустую строку ввода, не знают, что спросить. Все это открывает возможности для уровня приложений.
Еще два года назад многие компании, работающие на уровне приложений, высмеивались как «просто обертки под GPT-3». Сегодня оказывается, что эти «обертки» — один из немногих надежных способов создавать устойчивую ценность. То, что начиналось как «обертки», превратилось в «когнитивные архитектуры».
- Компании, создающие AI на уровне приложений, — это не просто UI, работающий поверх фундаментальной модели. Далеко не так. Они используют сложные когнитивные архитектуры, которые, как правило, включают:
- несколько фундаментальных моделей с механизмом маршрутизации;
- векторные и/или графовые базы данных для RAG (retrieval-augmented generation);
- защитные механизмы для соблюдения норм и правил;
- логику приложения, которая имитирует человеческий подход к обдумыванию рабочего процесса.
Service-as-a-Software
Переход в облачные технологии стал эрой software-as-a-service. Компании-производители ПО превратились в поставщиков облачных услуг, что создало рынок стоимостью в $350 миллиардов.
Благодаря созданию AI-агентов начинается переход к модели service-as-a-software. Производители ПО превращают труд в программное обеспечение. Это означает, что их рынок — это не рынок программного обеспечения, а рынок услуг, оцениваемый в триллионы долларов.

Что значит продавать работу? Хороший пример — . B2C-компании размещают Sierra на своих сайтах, чтобы взаимодействовать с клиентами. Задача — решить проблему клиента. Sierra получает оплату за каждое решение. Никаких «мест» или подписок не существует. У вас есть задача — Sierra ее выполняет и получает оплату соответственно.
Для многих компаний в сфере AI это и есть главная цель. Sierra выигрывает благодаря возможности переадресовать задачу к агенту-человеку, если AI не справился. Не всем компаниям так везет. Появляется новая схема: сначала система внедряется как copilot first (human-in-the-loop) и накапливает опыт, чтобы заслужить право работать как autopilot (без участия человека). Примером может служить GitHub Copilot.
AI-агенты — новый класс приложений
С развитием возможностей рассуждения генеративного AI появляется новый класс приложений, построенных на базе AI-агентов.
Интересно, что эти компании отличаются от своих предшественников в облачной сфере:
- Облачные компании нацеливались на прибыль от программного обеспечения. AI-компании нацеливаются на прибыль от услуг.
- Облачные компании продавали программное обеспечение (оплата за место). AI-компании продают работу (оплата за результат).
- Облачные компании предпочитали стратегию дистрибуции снизу вверх (bottom-up). AI-компании все чаще выбирают стратегию сверху вниз (top-down) с моделью дистрибуции, основанной на доверии.
Мы видим, как новый класс приложений появляется в различных секторах экономики знаний. Вот несколько примеров:
- Harvey: AI-юрист
- Glean: AI-ассистент по работе
- Factory: AI-программист
- Abridge: AI-агент для ведения медицинских записей
- XBOW: AI-пентестер
- Sierra: AI-агент по поддержке клиентов
Снижая предельные затраты на предоставление этих услуг — в соответствии с падающей стоимостью генерации ответа — эти AI-приложения расширяются и создают новые рынки.
Возьмем, например, XBOW. XBOW разрабатывает AI-пентестера. Пентест (или тест на проникновение) — это имитация кибератаки на компьютерную систему, которую компании проводят для оценки своих систем безопасности. До появления генеративного AI компании нанимали пентестеров только в ограниченных случаях (например, когда этого требовалось стандартами и регуляторами), потому что человеческий пентест — это дорогая услуга: это ручная работа, выполняемая высококвалифицированным специалистом. Однако теперь автоматизированные пентесты, построенные на новейших моделях AI, которые сопоставимы с производительностью самых высококвалифицированных пентестеров. Это умножает рынок пентестинга и открывает возможность для постоянного пентестинга для компаний любого размера.
Что это значит для вселенной SaaS?
Ранее в этом году мы встретились с партнерами нашего фонда. Их главный вопрос был: «Уничтожит ли переход к AI существующие облачные компании?»
Мы начали с уверенного ответа «нет». Классическая битва между стартапами и действующими игроками — это скачки, где стартапы строят дистрибуцию, а действующие компании — продукт. Могут ли молодые компании с крутыми продуктами добиться большого числа клиентов до того, как действующие компании, у которых уже есть пул клиентов, предложат крутые продукты? Учитывая, что большая часть магии AI приходит от фундаментальных моделей, наше исходное предположение было таковым: нет — действующим компаниям не о чем переживать, потому что фундаментальные модели доступны им так же, как и стартапам, а у них уже есть преимущества в виде данных и дистрибуции. Основная возможность для стартапов — это не замена существующих программных компаний, а нацеленность на автоматизируемые области работы.
Сейчас мы уже не так уверены. Для того чтобы превратить исходные возможности модели в убедительное, надежное, комплексное бизнес-решение, требуется огромное количество инженерных усилий. А что если мы просто сильно недооценили, что значит быть “AI native”?
Двадцать лет назад компании, разрабатывающие on-premises программное обеспечение, насмешливо относились к идее SaaS. «В чем проблема? Мы можем запускать свои серверы и так же доставлять это через интернет!» Конечно, концептуально это было просто. Но за этим последовало полноценное переизобретение бизнеса.
А что если AI — это аналогичный сдвиг? Может быть, возможность для AI заключается не только в продаже работы, но и в замене ПО?
Стартап Day.ai уже позволил взглянуть в будущее. Day — это CRM, построенная с использованием AI. Системные интеграторы зарабатывают миллиарды долларов, настраивая Salesforce под ваши нужды. С доступом только к вашей электронной почте и календарю, а также ответами на одностраничный опрос, Day автоматически генерирует CRM, идеально подстроенную под ваш бизнес. У нее еще нет всех привычных фичей (пока), но магия автогенерируемой CRM, которая остается актуальной без участия человека, уже подталкивает людей к переключению.
Инвестиционная вселенная
Куда мы направляем наши усилия как инвесторы? Во что мы инвестируем? Ниже — наше короткое саммари.
Инфраструктура
Это область компаний-hyperscalers (иными словами, это стремительно растущие компании, у которых сотни миллионов пользователей). Ею движет поведение, основанное на теории игр, а не микроэкономике. Это ужасное место для венчурного капитала.
Модели
Это также область компаний-hyperscalers и финансовых инвесторов. Они инвестируют деньги в компании-потребителей своих услуг/продуктов, инвестиции в итоге возвращаются обратно в виде доходов от облачных вычислений. Финансовые инвесторы слишком «ослеплены наукой». «Эти модели супер, а команды — просто невероятные. Микроэкономика? Да черт с ней!»
Инструменты для разработчиков и программное обеспечение для инфраструктуры
Менее интересно для стратегических инвесторов и более интересно для венчурных капиталистов. Примерно 15 компаний с доходом более $1 млрд было создано в этом сегменте во время перехода в облака, и мы предполагаем, что то же самое может произойти и с AI.
Приложения
Самый интересный сегмент для венчурного капитала. Примерно 20 компаний в этом сегменте с доходом более $1 млрд были созданы во время перехода в облака, еще около 20 — во время перехода на мобильные технологии, и мы предполагаем, что то же самое будет верно и для AI.

Заключительные мысли
В следующем акте развития генеративного AI мы ожидаем, что влияние исследований в области «мышления» начнет ощущаться на уровне приложений. Эти изменения будут быстрыми и глубокими. Когда возможности «мышления» станут глубже встроенными в модели, мы ожидаем, что AI-агенты станут гораздо более сложными и устойчивыми — и это произойдет быстро.
В исследовательских лабораториях рассуждения и вычисления на этапе генерации ответа будут продолжать оставаться важной темой в обозримом будущем. Теперь, когда у нас есть новый закон масштабирования, начинается следующая гонка. Но для любой конкретной области все еще сложно собирать данные из реального мира и разрабатывать когнитивные архитектуры, специфичные для этой области и продукта. И вновь приложения «последней мили» могут получить преимущество в решении разнообразных проблем в реальном мире.
Заглядывая в будущее, мультиагентные системы, такие как «дроиды» Factory, могут начать распространяться как способы моделирования процессов мышления и обучения внутри социума.
Мы все с нетерпением ожидаем «Хода 37» генеративного AI — того момента, когда, как в игре AlphaGo против Ли Седоля, AI-система удивит нас чем-то сверхчеловеческим. Чем-то, что будет ощущаться как независимая мысль. Это не значит, что AI «проснется» (AlphaGo этого не сделал), а что мы сможем смоделировать процессы восприятия, рассуждения и действий, которые AI сможет исследовать новыми и полезными способами. Возможно, это и будет сильный искусственный интеллект (AGI), и если это так, то это не будет неким единичным событием, а станет просто следующей фазой развития технологий.
*Meta (признана в России экстремистской организацией и запрещена)
**Instagram принадлежит Meta (признана в России экстремистской организацией и запрещена)