
Продукты на основе генеративного искусственного интеллекта стремительно ворвались в нашу реальность за последний год.
Еще несколько лет назад было сложно представить, что модели смогут генерировать изображения на основе текста или писать эссе в форме стихов на заданную тему. Причем делать это на уровне, который не уступает человеку. Сегодня продуктами на основе таких моделей пользуются миллионы людей, решая самые разнообразные задачи.
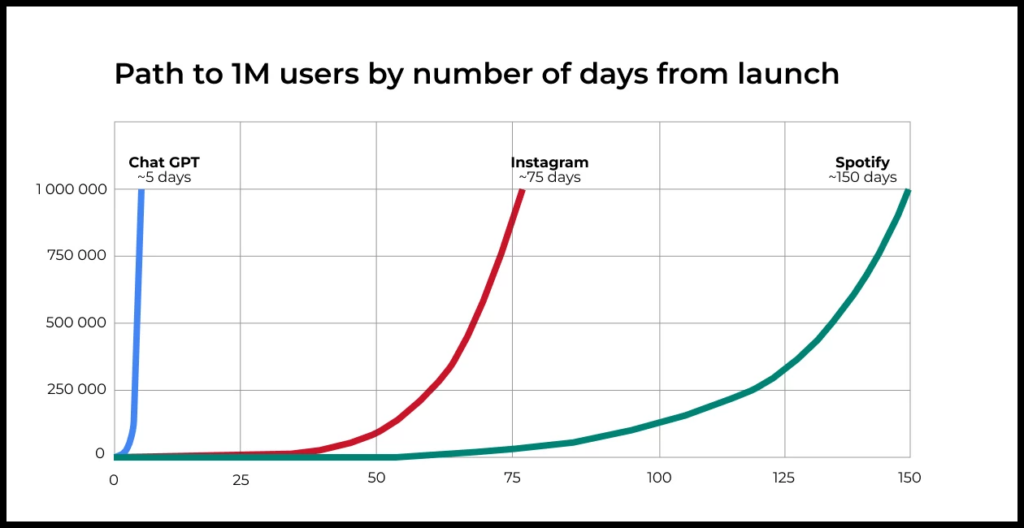
ChatGPT — один из самых ярких примеров продуктов, построенных на основе генеративного AI. Несмотря на отсутствие традиционного маркетинга, ему удалось стать самым быстрорастущим сервисом в истории.
Все материалы серии об использовании ML/AI в создании продуктов
1. Зачем продакт-менеджеру изучать ML и AI
2. Большие языковые модели: основы для тех, кто хочет строить продукты на их базе
3. Как ML-технологии помогают улучшать Retention продуктов
4. Как найти возможности для применения AI в вашем продукте
5. Базовое руководство для улучшения качества продуктов с LLM
6. Продвинутые методы улучшения качества продуктов с LLM: RAG
7. Почему идеальной ML-модели недостаточно, чтобы построить бизнес вокруг ML
8. Внедрение ML/AI для оптимизации процессов службы поддержки в крупном продукте: разбор кейса
9. AI-cтартапы: продавайте результат работы, а не софт
10. Новый этап развития генеративного AI: что это значит для стартапов и инвесторов?
Для многих такие технологии выглядят как магия, которая открывает невероятные возможности. Бизнес не стал исключением в погоне за этими возможностями: CEO и основатели компаний начали активно требовать от своих команд найти способы внедрения решений на базе генеративного AI в свои продукты.
Но чтобы действительно создать ценность с помощью этих технологий, необходимо понимать их основы: как они работают, где именно принесут пользу, какие у них ограничения и риски.
В этом материале мы простыми словами и без сложной математики разберем, как работают большие языковые модели (подмножество технологии генеративного AI для работы с текстом). Это позволит вам понимать возможности и степени свободы этой технологии, чтобы строить на ее основе новые продукты.
Курс «AI/ML-симулятор для продакт-менеджеров» в группе с ментором:
🔹 Научитесь видеть возможности для применения AI/ML в вашей текущей роли
🔹 Запустите собственный продукт с AI/ML→ ←
Принцип работы больших языковых моделей
Термин большие языковые модели (large language models, LLM) не имеет строгого определения, обычно под ним понимают модели, которые содержат огромное количество параметров (миллиарды) и были обучены на огромных объемах текстовых данных.
Принцип работы таких моделей достаточно прост:
- Модель получает на вход «промпт» (запрос от пользователя или набор слов) и далее подбирает наиболее подходящее следующее слово.
- После этого полученная строка вновь подается на вход модели и она подбирает еще одно слово.
- И так далее.
Так получается «разумное продолжение» на основе изначального запроса. Для пользователя это выглядит как ответ, который имеет смысл.
Промпт (prompt, подсказка, затравка) в данном случае — главный элемент управления. Генерация текста происходит именно на основе исходного запроса, поэтому, меняя и оптимизируя промпт, можно улучшать результат работы модели.
Как LLM генерирует связный текст
Для начала рассмотрим то, как именно LLM генерирует разумное продолжение.
Допустим, модель начала свой ответ с фразы «AI сегодня преобразует». Как она строит разумное предложение дальше?
Представьте, что мы просканировали весь интернет и нашли все случаи, где упоминается фраза «AI сегодня преобразует».
После этого мы взяли все слова, следующие за этой строкой, и вычислили, с какой вероятностью встречалось каждое из них. Например, мы могли получить следующий результат:

После этого на основе этих вероятностей можно выбрать следующее слово. В данном случае модель может добавить к «AI сегодня преобразует» слово «все». Но она может выбрать и иное слово: это зависит от настроек модели и решаемой задачи. Например, для креативных задач хорошо работает механика, когда не всегда выбирается слово с максимальной вероятностью. Это делает язык более «живым» и более оригинальным.
Следующим шагом можно повторить эти действия, используя строку с добавленным новым словом — «AI сегодня преобразует все». Задача LLM — определять, каким должно быть следующее слово на основе текста, который подан ей на вход. После добавления нового слова запускается процесс поиска следующего слова — и так далее.
В примере выше мы схематично показали, как работает LLM на примере подбора следующих слов предложения. При этом в реальности LLM работает не со словами, а со смыслом слов и предложений. Давайте обсудим, что это значит.
Как LLM понимает смысл текста
Приведенное выше объяснение — лишь вершина айсберга. На сегодня нельзя с уверенностью и простыми словами объяснить, как именно LLM «понимает» текст, но можно выделить несколько важных компонентов этого процесса:
LLM представляет каждое слово как точку в многомерном пространстве. Это пространство обычно очень сложное. Например, в моделях GPT-3 размерность около 10 000, то есть для описания каждого слова используется набор из около 10 000 чисел, который называется термином эмбеддинг (embedding).
↓
За счет обучения на огромном объеме данных получается добиться того, что близкие по смыслу слова становятся близкими точками, и математические операции над ними (сравнение близости, сложение, усреднение и так далее) начинают иметь практический смысл. Это позволяет модели находить синонимы, сравнивать смысл текстов, перефразировать тексты. Таким образом, модель работает не с фактическими словами, а с их смыслами.
↓
LLM моделирует взаимосвязи между словами. При определении следующего слова, его вероятность будет зависеть от смысла всех предыдущих слов с учетом их позиции в тексте. Этот механизм получил название causal self attention, именно он позволяет модели понимать смысл слов в зависимости от контекста их использования.
↓
Для обучения модели используются огромные массивы текстов. Современные модели могут обучаться на десятках терабайтов текста. Это дает возможность проанализировать настолько большое количество информации, что модель получает в некотором смысле универсальное знание практически обо всем. При этом стоит учитывать, что это знание напрямую зависит от того, на чем модель училась (это запросто могут быть не совсем достоверные данные).
↓
Сама модель имеет очень большое число параметров: десятки, а иногда сотни миллиардов параметров. За счет этого получается «запомнить» все стандартные конструкции большого числа языков, включая языки программирования, смыслы слов и терминов, стили текста и правила логических рассуждений.
↓
Универсальная языковая модель затем часто дообучается под конкретную задачу. Задачей может быть диалог, ответы на вопросы, дополнение или редактирование текста, классификация. Дообучение (fine-tuning) происходит с использованием данных, которые отражают специфику конечной задачи. Например, для дообучения ChatGPT (в качестве фундаментальной модели используется GPT-3.5 и GPT-4) использовались большие выборки вопросов и ответов в диалоговой форме, которые тщательно составлялись коллективом экспертов. Также для дообучения используется ручная разметка ответов, которые были созданы моделью с целью различить подходящие и неподходящие ответы. Именно дообучение позволяет добиться того, чтобы модель следовала инструкциям, которые указываются в промпте.
Риски и особенности применения LLM
Если вы думаете об использовании LLM в своем продукте или же построении нового сервиса, важно учитывать следующее.
Во-первых, LLM может сгенерировать все, что угодно. Ответы современных моделей не проходят фактчекинг. Это означает, что вы можете получить в ответ недостоверную, опасную или токсичную информацию. Эта проблема получила название AI-галлюцинаций и сейчас ведущих ученых.
- Использование информации, не прошедшей проверку, может обернуться .
- Недостоверная информация, созданная с помощью LLM, уже становится причиной .
- Люди склонны доверять ответам LLM — это создает угрозы .
Во-вторых, размер текста, который можно задавать на вход модели, ограничен, размер ответа модели также имеет ограничения.
- Это означает, что если вы хотите обработать текст большого размера, например сделать перевод книги или написать выжимку из длинной статьи или дать ответ, согласно длинной инструкции, то для этого потребуется придумать алгоритм обработки текста по частям.
В-третьих, важно осознавать риски, связанные с передачей персональных и иных корпоративных данных, при использования моделей через API облачных сервисов.
- Уже есть громкие случаи утечек корпоративных данных в ChatGPT — .
- Некоторые крупные компании вводят правила, запрещающие сотрудникам использовать ChatGPT — .
- Утечки данных могут произойти внутри самих облачных сервисов — .
Как оценить перспективы использования LLM в своем продукте
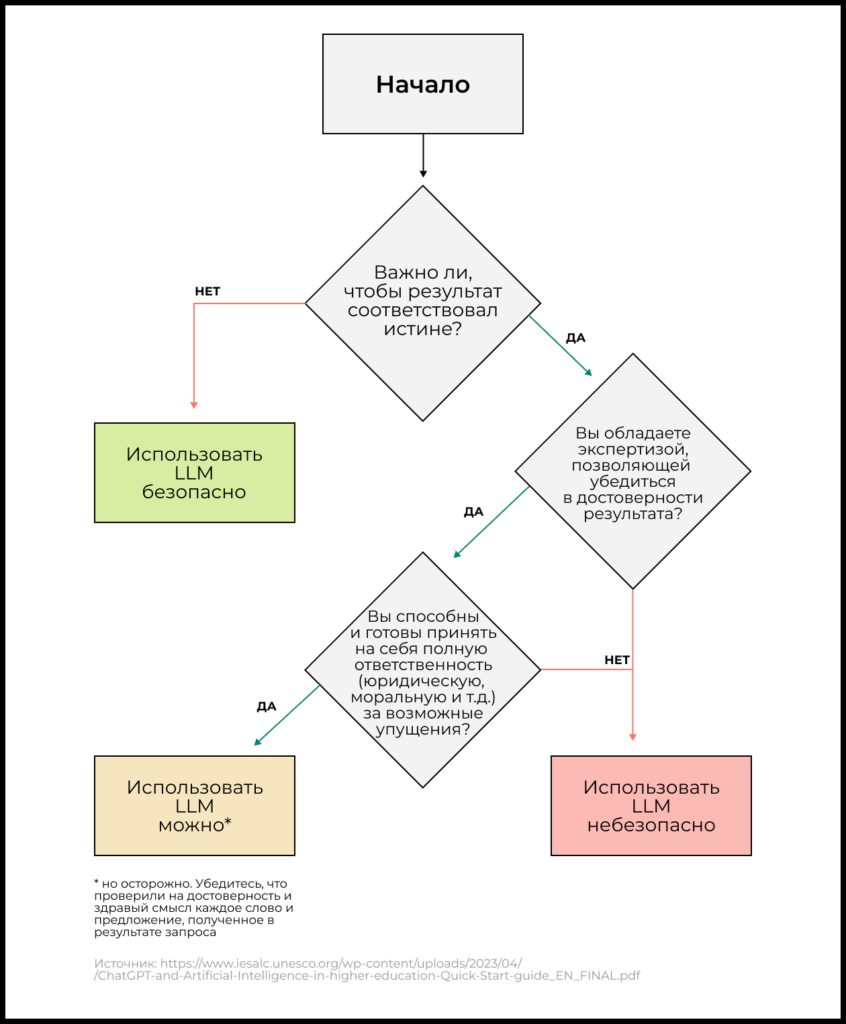
Чтобы принять решение об использовании LLM в вашем продукте, постарайтесь ответить на вопрос: «Если модель сгенерирует неправдоподобную/ложную/токсичную информацию, будет ли это безопасно для пользователя?»
- Если да — LLM можно использовать.
- Если нет — лучше либо воздержаться от использования технологии в вашем продукте, либо продумать и реализовать необходимые правила фильтрации такого контента, чтобы минимизировать риски.
Для использования LLM в продуктах и сервисах наиболее безопасны кейсы, когда ответ модели проходит дополнительную обработку сценариями верификации или используется в качестве ассистента-помощника для человека, который осознает ограничения этой технологии и не допускает реализации негативных рисков.
Примеры крупных продуктов на базе LLM
Вот несколько примеров новых успешных продуктов, которые построены на основе LLM моделей. Более полный список успешных кейсов применения LLM для конечного пользователя мы рассмотрим в следующих материалах цикла.
- – универсальный чат-бот;
- — новый интерфейс поисковой системы Bing, построенный на технологии LLM;
- — предоставляют API для встраивания LLM в продукты, например на базе этого API построена фича “Ask AI” в Notion;
- , который, по GitHub, сегодня участвует в написании 46% кода (среди разработчиков, которые его используют) и помогает им писать код на 55% быстрее;
- — сервис для создания контента сайтов, постов в блогах и социальных сетях;
- – диалоговая поисковая система.
Продолжение серии про генеративный AI
Этот материал — первый в серии публикаций о возможностях генеративного AI: какие существуют инструменты и перспективные бизнесы на их основе, какие возможности и ограничения есть у таких технологий.
Приобрести и отточить навыки управления продуктами с искусственным интеллектом и машинным обучением вам поможет «AI/ML-симулятор для продакт-менеджеров» от GoPractice.