
Большие языковые модели (Large Language Models, LLM) могут быть ценным помощником при автоматизации задач в работе над продуктом, что позволяет сэкономить деньги и время сотрудников. Впрочем, применение подобных инструментов не гарантирует получение качественных результатов сразу, что ставит вопрос о подходах по улучшению этих результатов.
Существует несколько основных подходов, и в этом материале мы разберем базовые, но действенные методы улучшения качества фичей и целых продуктов на основе LLM.
Рычаги влияния на качество продукта c LLM
Упрощенную схему типового продукта или фичи на основе LLM можно представить так:
- Есть задача пользователя, которую необходимо решить.
- На основе понимания задачи формируется промпт.
- Промпт передается в заданную LLM.
- LLM формирует ответ, который определенным образом обрабатывается в продукте и возвращается пользователю.
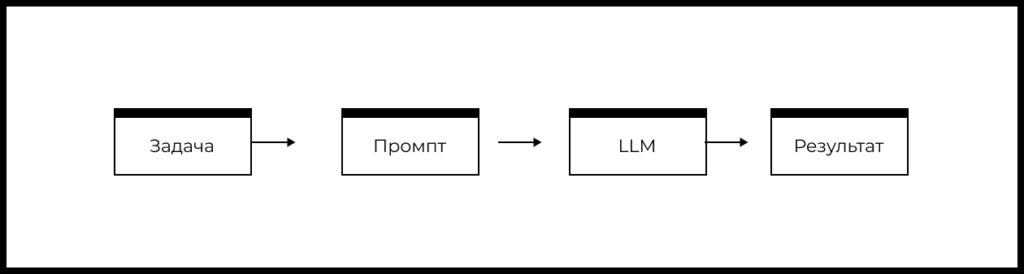
На основе блок-схемы выше можно выделить следующие рычаги влияния на качество фичи или продукта на базе LLM:
- Какая задача решается с помощью LLM.
- Как сформирован промпт.
- Какая используется модель и ее параметры.
Затем можно выделить базовые методы влияния на качество продуктов с LLM:
- Улучшение промпта.
- Эксперименты с моделями и их параметрами.
- Изменение решаемой задачи.
Если базовые методы не помогли улучшить качество результата до желаемого, то можно переходить к продвинутым методам:
- Retrieval-Augmented Generation (RAG, генерация на базе результатов поиска).
- Fine-tuning LLM (дообучение большой языковой модели).
- Few-Shot Learning.
- Использование внешних источников данных и сервисов.
- Использование пайплайна промптов и LLM-ансамблей.
- Переход от сущностей в промпте к идентификаторам.
- Перепроверка ответов LLM.
В этом материале мы сосредоточимся на базовых методах влияния на качество. В будущих материалах этого цикла поговорим про продвинутые методы.
Курс «AI/ML-симулятор для продакт-менеджеров» в группе с ментором:
🔹 Научитесь видеть возможности для применения AI/ML в вашей текущей роли
🔹 Запустите собственный продукт с AI/ML→ ←
Улучшение промпта
Краткое описание метода
Если текущее качество ответов модели вас не удовлетворяет (при условии, что вы умеете измерять качество ответов модели и понимаете целевое значение для вашего продукта), попробуйте сделать с вашим промптом следующее
Используйте четкие и подробные инструкции
- Указывайте, в какой роли выступает модель, когда она должна формировать ответ. Например, вы можете поручить ей выступать в роли продакт-менеджера или аналитика, который проводит исследование и анализирует фидбек пользователей.
- Используйте разделители смысловых блоков, такие как “”, ===, < >, <tag> </tag>. При этом формальных рекомендаций того, в каких случаях какие разделители использовать, нет; главное, чтобы разные смысловые блоки были явным образом разделены.
- Задавайте формат ответа: JSON, HTML, таблица или другой.
- Просите модель перепроверять, удовлетворяются ли все необходимые условия.
Дайте модели «время подумать»
- Перечисляйте инструкции для исполнения задачи как четкую последовательность шагов. Пример: Шаг 1: сделай X , Шаг 2: сделай Y , …., Шаг N: сделай Q.
- Добавляйте в промпт инструкцию «Решай задачу шаг за шагом» (‘Solve the problem step by step’).
- Просите модель дать объяснение для ее ответов.
Улучшение промпта: когда стоит применять
Улучшением промптов следует заниматься, когда LLM уже показывает нормальные результаты, но доля верных ответов все еще ниже целевого уровня.
Полезность рекомендаций следует проверять отдельно в каждой конкретной задаче.
Улучшение промпта: пример применения
Представьте, что вам нужно анализировать отзывы пользователей о продукте. Для этого вы хотите определять темы в отзывах и их тональность: позитивную, нейтральную или негативную.
Для иллюстрации мы подготовили промпт (назовем его промпт V1). {{Review text}} — это текст отзыва пользователя. Мы будем использовать английский язык, поэтому если вам требуется перевод, то можно обратиться к любому онлайн-переводчику (например, Google Translate, DeepL).
Промпт V1:
You are a product manager who has to research user experience of your app.
Your task is to analyze a review and extract main topics (maximum 3 topics).
For each topic extract related sentiment – positive/negative/neutral.
Here is a text of a review.
===
{{Review text}}
===
Output a RAW json with format
{
«topic_name»: «sentiment», …
}
На о приложении Twitter (X) из App Store такой промпт сработал плохо:
| Версия промпта | Доля релевантных тем | Доля релевантных тем промпта | Доля тем с верной тональностью |
|---|---|---|---|
| Промпт V1 GPT-3.5 | 0.64 | 0.13 | 0.88 |
Теперь воспользуется рекомендациями для улучшения промпта и попробуем промпт V2 (где {{Review text}} — это текст отзыва пользователя):
You are a product manager who has to research user experience of your app.
You must analyze the following review and extract the main topics about the app (maximum 3 topics, minimum – 0 topics).
Each topic has to describe an exact feature or issue of the app. It should be actionable for a product manager.
If there are no exact topics about the app in the review, then return «No topics».
Step 1: Extract the first main topic about the app.
Step 2: Extract the second main topic about the app. Compare this topic with the first one. If they are similar, then only use the first topic.
Step 3: Extract the third main topic about the app. Compare this topic with the first and the second ones. If they are similar, then use only previous topics.
Step 4: Check if extracted topics are really about exact features or issues of the app.
If not, then return «No topics».
Step 5: If you extracted topics, then for each extracted topic, define the sentiment in the review
– positive/negative/neutral.
Sentiment has to be related to user’s perception in the present, words such «now» could describe current sentiment.
Here is a text of a review.
===
{{Review text}}
===
Solve this task step by step.
Output a RAW json array with format
[{
«explanation»: «explain your decision here»,
«topic_name»: «extracted_name»,
«sentiment»: «extracted_sentiment»
}, …]
Что изменилось:
- Более четкие инструкции касательно количества тем, а также отдельная логика для ответа при отсутствии релевантных тем:
- “maximum 3 topics, minimum — 0 topics”
- “If there are no exact topics about the app in the review, then return «No topics».
- Порядок конкретных шагов для выделения тем в отзыве:
“Step 1: extract the first main topic about the app.
Step 2: extract the second main topic about the app. Compare this topic with the first one. If they are similar, then use only the first topic.
Step 3: extract the third main topic about the app.
Compare this topic with the first and the second ones. If they are similar, then use only previous topics.
Step 4: Check if extracted topics are really about exact features or issue of the app? If no, then return «No topics».
Step 5: If you extracted topics, then for each extracted topic define related sentiment – positive/negative/neutral.»
Для промпта V2 зафиксировано улучшение основных метрик: релевантности и избыточности ().
| Версия промпта | Доля релевантных тем | Доля избыточных тем | Доля тем с верной тональностью |
|---|---|---|---|
| Промпт V1 GPT-3.5 | 0.64 | 0.13 | 0.88 |
| Промпт V2 GPT-3.5 | 0.72 | 0.13 | 0.85 |
Подробнее кейс автоматического анализа отзывов пользователей с помощью GPT мы разбираем в нашем мини-симуляторе «Генеративный AI для продакт-менеджеров».
Эксперименты с моделями и их параметрами
Эксперименты с моделями и их параметрами: краткое описание метода
Для улучшения качества вашего решения полезно проводить эксперименты с заменой используемой LLM и подбором ее оптимальных параметров.
На рынке постоянно появляются новые модели, обновляются старые, меняются условия работы с ними (стоимость, API, регуляции).
Примеры популярных моделей: , , , , , , , . Обзор лидеров среди открытых LLM: .
В зависимости от решаемой задачи вы можете столкнуться с тем, что модели разных вендоров (например, OpenAI vs Anthropic vs Google) могут давать существенно разное качество.
Более продвинутые большие языковые модели почти всегда способны дать более качественный ответ. Например, результат модели GPT-4 будет почти всегда превосходить по качеству результат модели GPT-3.5. Ориентироваться среди версий GPT-моделей, например, от OpenAI вам поможет .
При этом использование более продвинутой модели не всегда будет оправдано, так как часто ее стоимость будет выше, а для ряда задач и более простые модели будут давать схожий результат.
Для некоторых задач полезно экспериментировать с параметрами моделей, например с температурой и указанием количества выходных .
Температура отвечает за вариативность ответов: чем выше значение температуры, тем более вариативным будет ответ LLM. Более высокое значение температуры больше подходит для креативных задач, например если вам надо придумать название для новой игры или сочинить рекламный слоган. При работе с GPT-4 для некоторых задач результат получается стабильно лучше с температурой 1, а не 0.
Для GPT-моделей указание количества выходных токенов может оказать сильное влияние на то, какой ответ вы получите. Даже короткие ответы могут сильно отличаться в зависимости от того, было ли указано количество выходных токенов или нет.
Эксперименты с моделями и их параметрами: когда стоит применять
Если вам не помогли базовые рекомендации по улучшению промпта, попробуйте использовать более продвинутую модель. В сложных задачах мы рекомендуем сразу начинать с использования наиболее продвинутых моделей.
Очень важно внимательно отслеживать изменения в используемых моделях, а также регулярно проводить эксперименты с новыми моделями и внедрять их, если это позволяет повысить ценность для бизнеса.
При экспериментах с новыми моделями держите в уме следующие детали:
- При изменении модели надо всегда заново оценивать качество.
- Для новых моделей может потребоваться заново подбирать промпты и заново проводить оценку качества на выборке примеров.
Новые модели могут существенно увеличить затраты на их использование, а могут и сократить, поэтому надо аккуратно оценивать оправданы ли издержки на новую модель с точки зрения экономики проекта или нет.
Использование более продвинутой модели: пример применения
Представьте, что вам требуется самостоятельно составлять описания товаров на вашем маркетплейсе, так как продавцы часто не загружают их или делают это плохо.
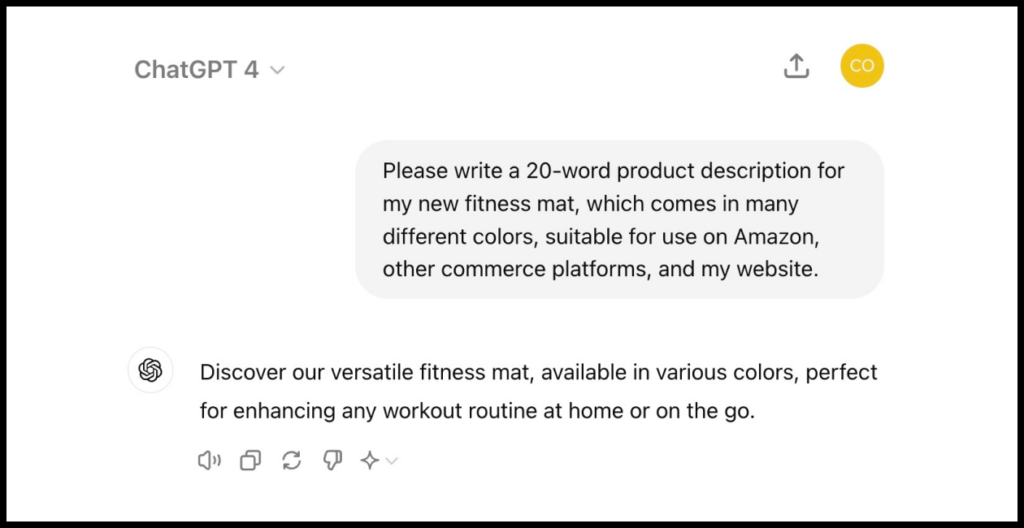
Давайте сравним результаты моделей GPT-4 и Claude-3.5 для такого промпта:
Please write me a 20-word product description for my new fitness mat, which comes in lots of different colors. Make it suitable for use on Amazon and other ecommerce platforms, as well as on my website.
Ответ GPT-4
Ответ Claude-3.5
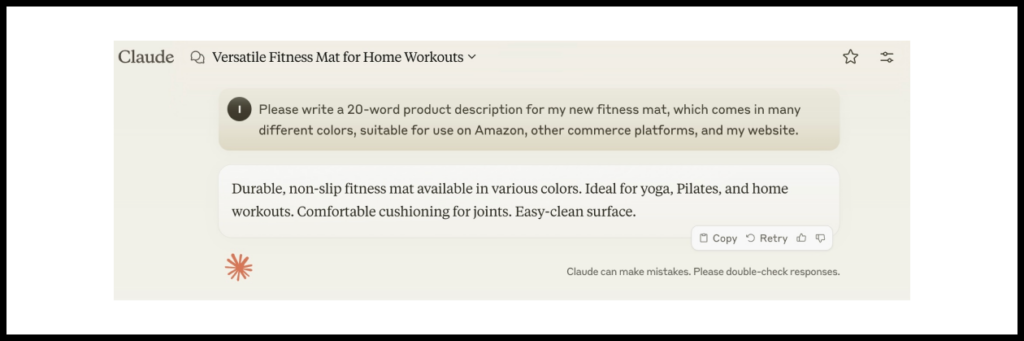
Для данного примера модель Claude-3.5 подобрала более интересное описание, которое лучше подходит для продвижения товара.
Изменение решаемой задачи
Изменение решаемой задачи: краткое описание метода
Иногда чтобы улучшить качество итогового решения и пользовательского опыта, исходную задачу стоит переформулировать, декомпозировать или вообще сузить до подзадачи.
Изменение решаемой задачи: когда стоит применять
Способ особенно актуален в следующих ситуациях.
Вы пытаетесь решать несколько задач одновременно с помощью одного промпта
↓
Попробуйте решать отдельные задачи отдельными более специализированными промптами.
Вы решаете задачу саммаризации документа и получаете плохое качество
↓
Попробуйте решать ее в два этапа – сначала извлеките конкретные поля, которые должны учитываться в саммаризации, а затем сформируйте шаблонный ответ на основе извлеченных полей.
Вы решаете задачу определения темы пользовательского сообщения в чате и сталкиваетесь с большим объемом сообщений, для которых тема непонятна
↓
Попробуйте перейти от задачи классификации к задаче диалога с пользователем, в рамках которого можно задать дополнительные вопросы.
Изменение решаемой задачи: пример применения
Рассмотрим пример анализа инвойсов клиента в банке. Если вы одним промптом попытаетесь саммаризовать информацию обо всех полях инвойса, то, скорее всего, получите низкое качество.
Для данной задачи хорошо подойдет комбинация двух подходов:
Переформулирование задачи
Лучше решать эту задачу не как саммаризацию информации, а как извлечение конкретных полей инвойса и формирование финального ответа по заданному шаблону. Важные поля инвойса — это наименования продавца и покупателя, сумма, дата оплаты, дата выставления инвойса, описание товара/услуги по инвойсу.
Декомпозиция
Для извлечения каждого из полей инвойса может быть полезным оптимизировать отдельный промпт.
Резюме
Мы рассмотрели базовые методы влияния на качество продуктов и фичей c LLM:
- Улучшение промпта.
- Эксперименты с моделями и их параметрами.
- Изменение решаемой задачи.
На практике чаще всего вы не можете предсказать, как будет выглядеть наиболее эффективное решение задачи. Поэтому в каждом случае стоит проводить эксперименты и оценивать качество на выборке примеров.
Если базовые подходы не помогли достигнуть необходимого качества, то стоит переходить к экспериментам с продвинутыми подходами, такими как:
- Retrieval-Augmented Generation (RAG, генерация на базе результатов поиска).
- Fine-tuning LLM (дообучение большой языковой модели).
- Few-Shot Learning.
- Использование внешних источников данных и сервисов.
- Использование пайплайна промптов и LLM-ансамблей.
- Переход от сущностей в промпте к идентификаторам.
- Перепроверка ответов LLM.
Мы будем разбирать эти продвинутые методы в следующих публикациях.
Все материалы серии об использовании ML/AI в создании продуктов
1. Зачем продакт-менеджеру изучать ML и AI
2. Большие языковые модели: основы для тех, кто хочет строить продукты на их базе
3. Как ML-технологии помогают улучшать Retention продуктов
4. Как найти возможности для применения AI в вашем продукте
5. Базовое руководство для улучшения качества продуктов с LLM
6. Продвинутые методы улучшения качества продуктов с LLM: RAG
7. Почему идеальной ML-модели недостаточно, чтобы построить бизнес вокруг ML
8. Внедрение ML/AI для оптимизации процессов службы поддержки в крупном продукте: разбор кейса
9. AI-cтартапы: продавайте результат работы, а не софт
10. Новый этап развития генеративного AI: что это значит для стартапов и инвесторов?
Прокачать навыки работы над AI-продуктами вам помогут:
Автор иллюстрации к материалу —