
В недавней публикации мы рассматривали базовые рекомендации для улучшения качества продуктов с LLM.
В этом материале мы разберем один из продвинутых подходов — Retrieval-Augmented Generation (RAG, или генерация на базе результатов поиска).
Схема типового продукта на основе LLM
Напомним упрощенную схему типового продукта или фичи на основе LLM:
- Есть задача пользователя, которую необходимо решить.
- На основе понимания задачи формируется промпт.
- Промпт передается в LLM.
- LLM формирует ответ, который определенным образом обрабатывается в продукте и возвращается пользователю.
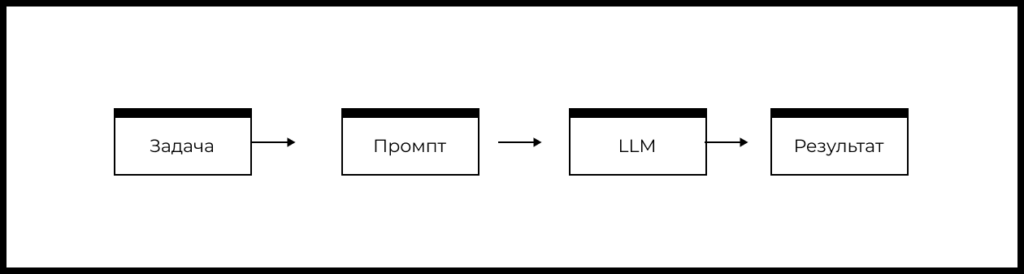
Исходя из блок-схемы выше мы можем выделить следующие рычаги влияния на качество фичи или продукта на базе LLM:
- Выбор задачи, которая решается с помощью LLM?
- Изменение промпта
- Изменение используемой модели и/или ее параметров?
С помощью RAG мы влияем преимущественно на то, как сформирован промпт, добавляя к нему дополнительную важную информацию для ответа.
Сначала мы разберем суть подхода и типовые ситуации, где RAG может быть полезен. После этого сделаем обзор реальных кейсов с применением RAG.
Курс «AI/ML-симулятор для продакт-менеджеров» в группе с ментором:
🔹 Научитесь видеть возможности для применения AI/ML в вашей текущей роли
🔹 Запустите собственный продукт с AI/ML→ ←
RAG: суть подхода для улучшения качества LLM продуктов
Идея RAG заключается в том, что мы обогащаем промпт дополнительными знаниями, которые отсутствовали в обучающем датасете большой языковой модели (LLM).
Существуют различные модификации RAG, но основные шаги подхода одинаковы:
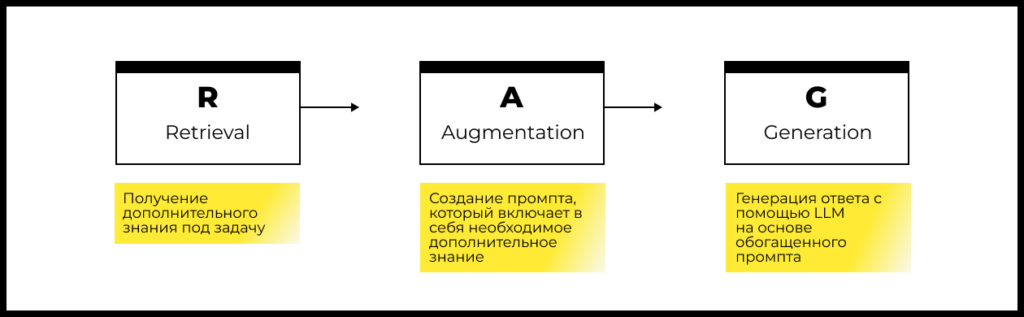
Шаг 1: Retrieval
На основе пользовательского запроса происходит обращение в заранее определенные источники данных. Источниками данных могут быть внутренние базы данных компании, документы, внешние ресурсы (например, поисковые системы, специализированные сервисы, API).
Поиск дополнительной информации осуществляется либо на основе исходного запроса пользователя, либо его трансформации (запрос пользователя может быть превращен в SQL-запрос, набор поисковых запросов, Embedding).
По результатам этого шага мы получаем дополнительные данные, которые обогащают базовую информацию, с которой работает LLM при ответе на вопрос.
Шаг 2: Augmentation
На этом шаге происходит формирование промпта, который содержит исходный пользовательский запрос и дополнительное знание, полученное на предыдущем шаге (Retrieval).
Результаты поиска можно менять, чтобы сделать обогащенный промпт наиболее точным, например с помощью фильтрации, дополнительного ранжирования, саммаризации, etc. Эти результаты всегда должны быть преобразованы в текст для использования в промпте.
По итогам этого шага мы получаем обогащенный промпт.
Шаг 3: Generation
На этом шаге обогащенный дополнительным знанием промпт отправляется в большую языковую модель (LLM). На ответ модели можно существенно влиять с помощью изменения параметров температуры и количества выходных токенов.
Ответ модели может быть модифицирован, например с помощью добавления цитат или ссылок на источники дополнительного знания, которое использовалось в обогащенном промпте. Можно также реализовать дополнительную верификацию ответа модели.
На основе результата этого шага далее формируется ответ для пользователя.
Когда использовать RAG
RAG может помочь, если необходимо:
- Использовать информацию, которой не было в обучающем датасете LLM.
- Повысить надежность и уменьшить уровень галлюцинаций LLM.
- Предоставлять ссылки на источники информации, на основе которых был получен ответ.
Преимущества RAG:
- Относительно прост в реализации: для некоторых задач его можно реализовать всего .
- Более быстрый и менее затратный в сравнении с подходом Fine-tuning (дообучение большой языковой модели).
- Позволяет оперативно заменять источники для обогащения промптов.
Недостатки RAG:
- Чтобы использовать RAG в продакшене, нужно поддерживать специальную инфраструктуру, которая может оказаться довольно сложной (сложность зависит от конкретной задачи и источников данных для RAG).
- Оценка качества для RAG — это трудоемкий процесс. На результат влияет множество компонентов, и каждый из них нужно оценивать отдельно (создавать много тестовых датасетов, метрик и разметки). Например, если необходимо добавлять цитаты из источника данных, то качество цитирования необходимо измерять отдельно.
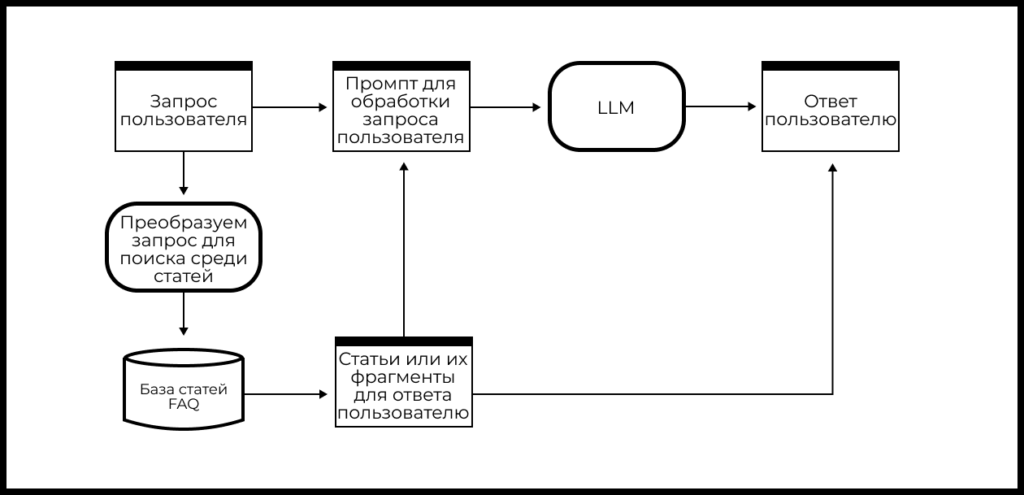
Кейс поиска по FAQ
Почти любая компания может превратить набор FAQ-документов (документов, отвечающих на наиболее частые вопросы пользователей) со своего сайта или из приложения в достаточно универсальный Q&A чат-бот, который сможет корректно отвечать на типичные вопросы пользователей с помощью LLM и RAG.
Схема реализации такого чат-бота на основе FAQ может выглядеть так:
- Делаем поиск среди статей FAQ, чтобы получить самую релевантную из них для запроса пользователя (если релевантных статей несколько, то формируем набор или отранжированный список).
- Формируем промпт на основе запроса пользователя и найденной информации из документа (набора документов).
- Отправляем обогащенный дополнительной информацией промпт в LLM и получаем ответ модели.
- Добавляем к ответу модели ссылки на статьи-источники и получаем ответ для пользователя.
Кейс персонального помощника для формирования продуктовой корзины
Представьте, что вы отвечаете за сервис по доставке продуктов питания и хотите внедрить новую фичу — персонального помощника. Он должен помогать пользователям корректировать их продуктовые корзины, чтобы, например, сделать питание более экономным или более разнообразным.
Реализовать такого помощника можно на основе LLM и RAG.
- Делаем запросы в API сервисов, которые предоставляют информацию об ассортименте товаров и ценах.
- Формируем промпт для определения того, является ли запрос ценовым или нет. Если да, то:
- Формируем промпт для рекомендации менее дорогих товаров, обогащенный информацией про цены товаров (RAG).
- Делаем перепроверку ответов модели, чтобы убедиться, что действительно все рекомендованные товары являются более дешевыми (это целесообразно, так как LLM не очень хорошо работают с математическими операциями).
- Если запрос нацелен на формирование более разнообразной корзины, то формируем промпт для рекомендации более разнообразных товаров.
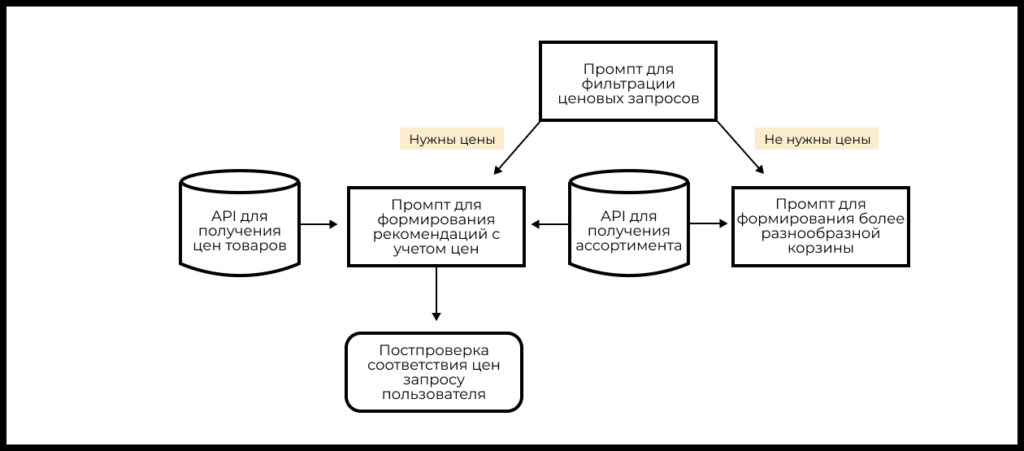
Кейс реализации персонального помощника для формирования корзины товаров (GPT + RAG) подробно рассматривается в «AI/ML-симуляторе для продакт-менеджеров».
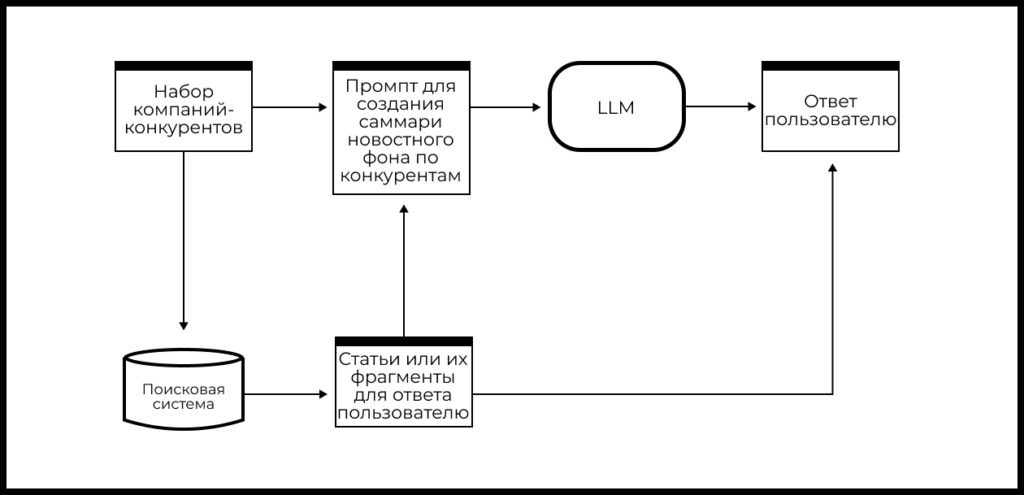
Саммаризация свежих новостей
Представьте, что вам необходимо регулярно следить за новостями компаний – конкурентов вашего продукта. Вместо ручного поиска и анализа новостей можно воспользоваться комбинацией LLM и RAG, которая позволит автоматизировать этот процесс.
Пусть у вас есть список компаний-конкурентов и вам надо анализировать новости о них ежедневно. Схема реализации пайплайна может выглядеть так:
- Делаем поиск свежих новостей с помощью поисковой системы (API).
- Скачиваем релевантные документы и делаем парсинг текста статей.
- На основе текстов статей формируем саммари новостного фона для каждой компании-конкурента (LLM).
- Добавляем к ответу модели ссылки на сайты-источники и получаем ответ.
RAG: резюме
Retrieval-Augmented Generation (RAG) — это один из мощнейших продвинутых подходов для улучшения качества продуктов с LLM. Его идея в том, что мы обогащаем промпт дополнительными знаниями, которые отсутствовали в обучающем датасете модели.
RAG может помочь, если необходимо:
- Использовать информацию, которая не присутствовала в обучающем датасете LLM.
- Повысить надежность и уменьшить уровень галлюцинаций LLM.
- Предоставлять ссылки на источники информации, на основе которых был получен ответ.
Преимущества RAG:
- Относительно прост в реализации: для некоторых задач его можно реализовать всего пятью строками кода.
- Более быстрый и менее затратный в сравнении с подходом Fine-tuning (дообучение большой языковой модели).
- Позволяет оперативно заменять источники для обогащения промптов.
Недостатки RAG:
- Чтобы использовать RAG в продакшене, нужно поддерживать специальную инфраструктуру, которая может оказаться довольно сложной (сложность зависит от конкретной задачи и источников данных для RAG).
- Оценка качества для RAG — это трудоемкий процесс. На результат влияет множество компонентов, и каждый из них нужно оценивать отдельно (создавать много тестовых датасетов, метрик и разметки). Например, если необходимо добавлять цитаты из источника данных, то качество цитирования необходимо измерять отдельно.
Все материалы серии об использовании ML/AI в создании продуктов
1. Зачем продакт-менеджеру изучать ML и AI
2. Большие языковые модели: основы для тех, кто хочет строить продукты на их базе
3. Как ML-технологии помогают улучшать Retention продуктов
4. Как найти возможности для применения AI в вашем продукте
5. Базовое руководство для улучшения качества продуктов с LLM
6. Продвинутые методы улучшения качества продуктов с LLM: RAG
7. Почему идеальной ML-модели недостаточно, чтобы построить бизнес вокруг ML
8. Внедрение ML/AI для оптимизации процессов службы поддержки в крупном продукте: разбор кейса
9. AI-cтартапы: продавайте результат работы, а не софт
10. Новый этап развития генеративного AI: что это значит для стартапов и инвесторов?
***
Прокачать навыки работы над AI-продуктами вам помогут:
Автор иллюстрации к материалу —