
В одной из предыдущих публикаций мы рассматривали базовые рекомендации для улучшения качества продуктов с LLM.
В этой статье мы разберем один из продвинутых подходов — Fine-tuning LLM (дообучение большой языковой модели).
Схема типового продукта на основе LLM
Напомним упрощенную схему типового продукта или фичи на основе LLM:
- Есть задача пользователя, которую необходимо решить.
- На основе понимания задачи формируется промпт.
- Промпт передается в LLM.
- LLM формирует ответ, который определенным образом обрабатывается в продукте и возвращается пользователю.
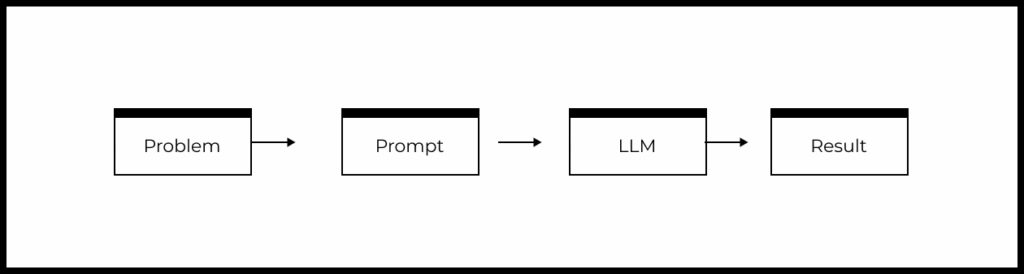
Исходя из блок-схемы выше, мы можем выделить следующие рычаги влияния на качество фичи или продукта на базе LLM:
- Выбор задачи, которая решается с помощью LLM.
- Изменение промпта.
- Изменение используемой модели и/или ее параметров.
С помощью Fine-tuning мы влияем на саму большую языковую модель, так как она дообучается на специфичных для решаемой задачи данных.
Сначала мы разберем суть подхода и типовые ситуации, где Fine-tuning может быть полезен. После этого сделаем обзор кейсов с применением Fine-tuning.
Курс «AI/ML-симулятор для продакт-менеджеров» в группе с ментором:
🔹 Научитесь видеть возможности для применения AI/ML в вашей текущей роли
🔹 Запустите собственный продукт с AI/ML→ ←
Fine-tuning: суть подхода для улучшения качества LLM продуктов
Fine-tuning — это дообучение большой языковой модели.
Дообучение — это процесс, при котором универсальная модель, уже обученная на большом объеме данных (например, GPT-4o mini), дополнительно обучается на новом, специализированном наборе данных, специфичном для решаемой задачи.
Этот процесс позволяет модели лучше справляться с конкретными задачами или понимать специфику новых данных.
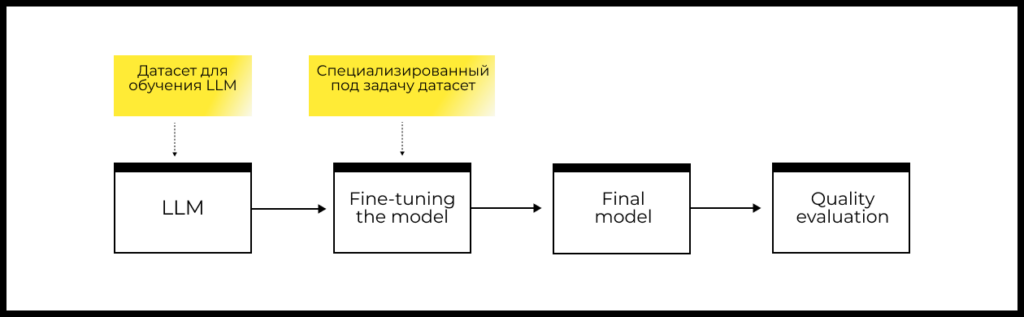
Для реализации fine-tuning вам нужны:
- Датасет, который содержит специфичные для вашей задачи примеры (достаточно нескольких сотен или тысяч примеров в датасете).
- Модель, которую можно дообучать: это либо открытая модель (LLaMa, Mistral и др.), либо облачный сервис дообучения вокруг коммерческой модели ().
- Процедура оценки качества решения.
Работу по дообучению LLMs обычно выполняет AI-инженер.
Когда использовать Fine-tuning
Fine-tuning может помочь, если необходимо:
- Работать со специализированными данными
- Делать классификацию документов
- Соблюдать строгую структуру/стиль ответов
- Оптимизировать скорость и стоимость использования LLM
Преимущества Fine-tuning:
Если вам необходимо достигнуть максимального доступного качества в обработке специализированных данных или в соблюдении сложной структуры / стиля ответа, то наилучший выбор — это Fine-tuning. Иные способы (RAG, оптимизация промпта, etc) не смогут превзойти Fine-tuning в качестве.
Недостатки Fine-tuning:
В применении данного подхода есть важное ограничение: для дообучения LLM необходим набор специфичных для решаемой задачи данных. Напомним, что требуется несколько сотен или тысяч примеров в датасете.
Даже при наличии достаточного объема данных реализация подхода — это сложная и иногда дорогостоящая задача.
Сложность решения на основе дообученной модели вызвана:
- Необходимостью наличия в команде квалифицированных инженеров, которые умеют работать с LLM.
- Большим количеством разных вариантов дообучения (разные модели, различные параметры, различные датасеты, изменение постановки задачи).
- Отсутствием гарантии успеха.
Стоимость решения складывается из стоимости:
- подготовки данных для дообучения;
- самого процесса дообучения LLM;
- подготовки инфраструктуры в компании.
Всегда полезно оценивать примерные сроки и стоимость до старта работы и далее принимать решение об их целесообразности для бизнеса.
С течением времени данные могут меняться, поэтому стоит предусматривать мониторинги и регулярный fine-tuning. Регулярное дообучение стоит также предусмотреть при оценке стоимости подхода.
Когда не надо делать fine-tuning
Держите в уме, что не стоит заниматься дообучением LLM, если вы создаете новый продукт и еще не достигли product-market-fit:
- На ранней стадии работы над продуктом в подавляющем большинстве случаев разумно использовать ведущие LLM (GPT-4o, Claude 3.5) без дообучения.
- Перед тем как рассматривать дообучение, нужно создать процесс оценки качества LLM-решений и иметь baseline для принятия решения о целесообразности экспериментов с дообучением.
Fine-tuning маленьких языковых моделей
Сейчас наблюдается тренд на использование маленьких языковых моделей (small language models, SLM), которые:
- Являются результатом дообучения стандартных маленьких open-source моделей и дообучается на результатах больших языковых моделей в определенной задаче.
- Позволяют существенно сокращать стоимость использования языковых моделей.
- Обеспечивают качество, сравнимое с наиболее мощными LLM в некоторых задачах.
- Снижают риски, связанные с передачей данных в сторонние облачные сервисы, поскольку они работают в контуре компании.
Кейс реализации AI-персонажа
Представьте, что вы хотите создать AI-персонажа, который будет говорить с вами, как Стив Джобс, соблюдая его стиль ответов по содержанию и форме.
Вам потребуется датасет, состоящий из как можно большего количества речей Стива Джобса. В данном случае:
- Датасет — это примеры речи Стива Джобса (просто набор текстов).
- При обучении языковой модели для формирования объекта и целевого значения используется принцип self-supervised learning. Это означает, что не требуется дополнительной разметки данных и объекты формируются автоматически из самого текста.
Этот датасет будет отражать специфику речи Джобса, и на нем можно дообучить большую языковую модель, например GPT-4o mini.
Рассмотрим пример из :
“I am honored to be with you today at your commencement from one of the finest universities in the world. I never graduated from college. Truth be told, this is the closest I’ve ever gotten to a college graduation. Today I want to tell you three stories from my life. That’s it. No big deal. Just three stories.”
Вспомним, что языковая модель решает задачу предсказания следующего слова на основе имеющегося текста (подробнее — в нашем прошлом материале «Большие языковые модели: основы для тех, кто хочет строить продукты на их базе»).
Наш фрагмент текста можно превратить в набор объектов исходя из этого принципа. Выберем для простоты окно в 10 слов для разбивки текста, вот что получится:
- I am honored to be with you today at your
- am honored to be with you today at your commencement
- honored to be with you today at your commencement from
- to be with you today at your commencement from one
- и так далее
Суть дообучения заключается в том, что языковой модели надо предсказывать десятое слово (это целевое значение) на основе девяти предыдущих (эти девять слов являются объектом).
Такая постановка задачи — это сильное упрощение, но она передает основной принцип.
Кейс AI-ассистента по законодательству
Представьте, что вы хотите создать AI-ассистента по вопросам законодательства конкретной страны или штата. Законодательные нормы существенно отличаются между странами. В таком случае для каждой страны целесообразно готовить отдельные датасеты с нормативными документами и проводить fine-tuning LLM для каждого датасета.
В отличии от предыдущего примера, задача состоит в формировании корректных ответов на юридические вопросы, а не новых юридических актов. Для такого случая потребуется использовать supervised fine-tuning:
- Нам потребуется размеченный датасет, состоящий из текстов в формате вида «вопрос — правильный ответ». В более общем виде это формат «промпт — правильный ответ».
- Тексты из размеченного датасета далее будут использоваться, чтобы генерировать объекты и целевые значения для дообучения.
Кейс анализа обращений в службу поддержки
Если вы хотите определять категорию обращений пользователей продукта в службу поддержки, вам может быть полезен fine-tuning.
В этом случае надо использовать supervised fine-tuning (как в прошлом примере):
- Нам потребуется размеченный датасет, состоящий из текстов в формате вида «текст обращения пользователя в службу поддержки — категория обращения».
- Целевым значением будет категория обращения. Обычно категории кодируются числами, чтобы задача модели свелась к предсказанию ровно одного токена.
- Объектом будет текст обращения.
Оценка качества fine-tuning
Для оценки качества fine-tuning используется принцип оценки обучения с учителем. Его суть:
- Необходимо сделать разбиение датасета на обучающий и тестовый датасеты.
- Обучающий датасет используется для процесса fine-tuning.
- Тестовый датасет используется для оценки качества fine-tuning.
Чтобы оценить прирост качества после дообучения, можно сравнить метрики после дообучения и метрики до дообучения (то есть при простом использовании большой языковой модели).
Fine-tuning — довольно сложный процесс с множеством параметров, поэтому всегда критически важно проводить оценку качества, чтобы понимать, действительно ли дообучение было сделано правильно и приносит пользу.
Fine-tuning LLM: резюме
Fine-tuning LLM — это дообучение универсальной модели на новом, более специализированном наборе данных.
Fine-tuning может помочь, если необходимо:
- Работать со специализированными данными.
- Делать классификацию документов.
- Соблюдать строгую структуру/стиль ответов.
- Оптимизировать скорость и стоимость использования LLM.
Преимущества fine-tuning:
Если вам необходимо достигнуть максимального доступного качества в обработке специализированных данных или в соблюдении сложной структуры / стиля ответа, то наилучший выбор — это Fine-tuning. Иные способы (RAG, оптимизация промпта, etc) не смогут превзойти Fine-tuning в качестве.
Недостатки fine-tuning:
В применении данного подхода есть важное ограничение: для дообучения LLM необходим набор специфичных для решаемой задачи данных (достаточно нескольких сотен или тысяч примеров в датасете).
Fine-tuning — довольно сложный процесс с множеством параметров, поэтому всегда критически важно проводить оценку качества, чтобы понимать, действительно ли дообучение было сделано правильно и приносит пользу.
Узнайте больше
- Базовое руководство для улучшения качества продуктов с LLM
- Продвинутые методы улучшения качества продуктов с LLM: RAG
Прокачайте навыки в наших симуляторах
Автор иллюстрации к материалу —