
Модель Кано — это гибридная методика исследования пользователей, сочетающая в себе элементы качественных и количественных исследований. Она позволяет изучить, что в продукте влияет на удовлетворенность пользователей через призму их эмоционального восприятия. Если говорить совсем просто, модель Кано помогает понять, что заставляет людей не просто использовать продукт, но любить его.
Этим инструментом пользуются как продакт-менеджеры, так и другие участники продуктовой команды — UX-исследователи, дизайнеры, маркетологи. В этом материале вы найдете гайд по применению модели Кано для своего продукта.
Краткая история метода
В семидесятые–восьмидесятые годы прошлого века Япония стремительно развивала производство автомобилей и электроники.
Одним из драйверов успеха для ведущих японских компаний вроде Toyota, Sony, Panasonic был подход TQM (Total Quality Management), суть которого сводилась к тому, что все сотрудники компании были ориентированы на поддержание наивысшего качества на всех этапах производства.
Если говорить упрощенно, то это повлекло за собой фокус именно на количестве и качестве фичей (чем больше их будет и чем точнее они будут работать — тем лучше), а не на том, нужны ли они, собственно, клиенту. И если да, то какой вклад в его удовлетворенность они вносят.
В 1984 японский профессор Нориаки Кано представил свой подход к изучению проблемы удовлетворенности. Он понял, что улучшение фичей имеет нелинейный эффект на ощущения клиентов.

Простой пример.
- Подход, основанный на TQM, подразумевал, что скорость, с которой кондиционер в машине добивается охлаждения, нужно постоянно повышать. Иными словами, бесконечно улучшать параметр.
- Подход Кано показал, что само по себе наличие хорошего кондиционера в машине радикально повышает удовлетворенность клиентов, но при этом скорость охлаждения в какой-то момент просто перестает иметь значение. А значит улучшение этого параметра уже не будет оказывать существенного влияния на фактор удовлетворенности.
Модель, которую представил профессор Кано, позволяет приоритизировать фичи именно на основе исследования эмоционального восприятия и удовлетворенности. Она стала не только важной частью японской производственной культуры, но и проникла в современную IT-индустрию, где применяется для исследования пользователей.
Какие задачи можно решить в продукте с помощью модели Кано
Основной параметр, которым оперирует модель Кано, это удовлетворенность пользователей. В управлении продуктом это прежде всего позволяет получить оценки для приоритизации.
Исследование по модели Кано требует ресурсов, поэтому обычно его применяют для среднесрочной–долгосрочной приоритизации (ближе к стратегическому уровню, нежели тактическому).
Когда модель эффективна:
- Углубленное исследование пользователей на этапе Discovery
- Долгосрочное планирование продуктовой стратегии
- Работа с UX-командой для понимания эмоционального опыта пользователей
- Поиск рычагов дифференциации в конкурентной среде
Когда модель не стоит использовать:
- При ограниченных ресурсах на исследования
- Для быстрой приоритизации бэклога (лучше подойдут фреймворки вроде ICE, RICE, MoSCoW)
- В ситуациях, когда функциональность продукта жестко регламентирована внешними факторами — стандартами, законодательством, техническими спецификациями (например, нет смысла спрашивать пользователей, как они относятся к шифрованию по определенному стандарту, если это обязательное требование)
- В продуктах, где очень сильно влияние стейкхолдеров, например, в сложных B2B-продуктах
Как модель Кано измеряет удовлетворенность пользователей
Модель делит фичи продукта на четыре основные категории:
- 🔴 Безусловно необходимые (Must-be). Наличие таких фичей обязательно. Оно не улучшает пользовательский опыт — это лишь «минимально допустимый уровень». Их отсутствие вызывает сильное недовольство.
Что могло бы быть примером по итогам исследования: просмотр баланса и истории операций в приложении банка. Если такой фичи нет, то во многих кейсах использования это сводит смысл приложения к нулю. - 🔵 Важные (Performance). Чем лучше качество и больше пользовательских возможностей, тем выше удовлетворенность.
Что могло бы быть примером по итогам исследования: разные способы денежных переводов другим людям через приложение банка. Чем больше вариантов (по номеру телефона, по номеру карты, по иным доступным признакам другого пользователя), тем лучше. - 🟢 Неожиданные и вызывающие восторг пользователя (Attractive или Delighters): Неочевидные функции, которые вызывают восторг, если они есть, но не влияют на отношение пользователя к продукту, если их нет.
Что могло бы быть примером по итогам исследования: открытие счетов в разных валютах к одной карте, между которыми можно обменивать по выгодному внутрибанковскому курсу. - ⚪️ Не влияющие на удовлетворенность продуктом (Indifferent): Атрибуты, не влияющие на удовлетворенность клиентов в любом состоянии.
Что могло бы быть примером по итогам исследования: анимация логотипа банка в приложении.
Иногда также добавляют пятую категорию: ⚫️ Обратные (Reverse): Функции, которые дают обратный эффект и вызывают недовольство.
Что могло бы быть примером по итогам исследования: принудительное обновление PIN-кода для входа в приложение каждую неделю.
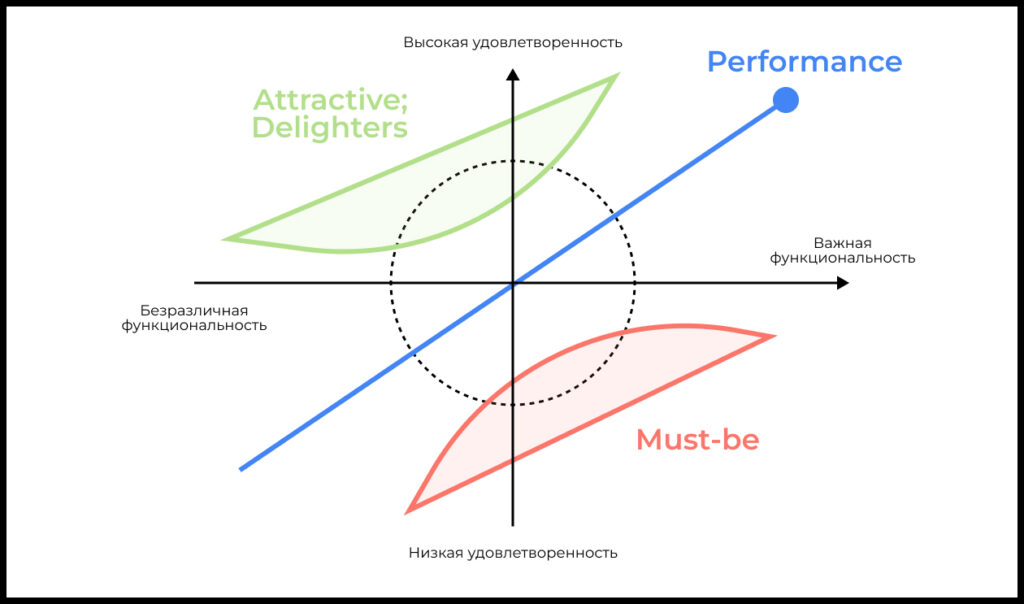
Идея в том, чтобы сосредоточить усилия на фичах, которые действительно создают ценность для клиентов:
- Must-be, без которых сервис не имеет смысла
- Performance, которых пользователи явно ожидают
- Attractive или Delighters, которые будут оценены пользователями
При этом избегать затрат ресурсов на фичи, которые не нужны или вредны:
- Indifferent, которые не влияют на удовлетворенность клиентов и не ожидаются ими
- Reverse, которые имеют негативный эффект
При этом важно, что модель Кано позволяет учитывать смещение оценки той или иной фичи по категориям. Классический пример — Touch ID от Apple.
Появившаяся в 2013 году биометрическая разблокировка была довольно революционной фичей и вызывала восторг пользователей. Затем стала стандартом для премиум-сегмента, а к 2020 году превратилась в базовое требование. Очевидно, что сегодня отсутствие биометрии в смартфоне воспринимается как серьезный недостаток.
Как применить модель Кано
Чтобы воспользоваться моделью Кано, нужно пройти два этапа:
- Проведение опроса
- Интерпретация результатов
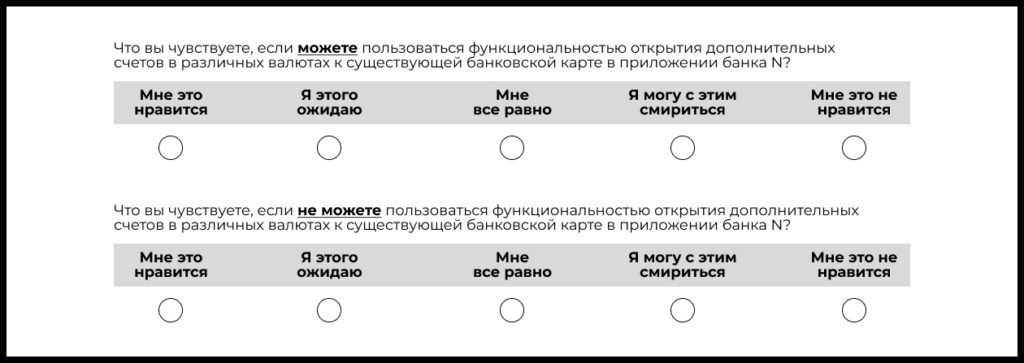
Ключевой метод — опросы с парными вопросами.
Суть в том, чтобы для каждого атрибута продукта сформулировать два типа вопросов.
1️⃣ Функциональный: «Как вы себя чувствуете, если фича Х присутствует в продукте?».
2️⃣ Дисфункциональный: «Как вы себя чувствуете, если фича Х отсутствует в продукте?».
Варианты ответов здесь:
- «Мне это нравится»
- «Я этого ожидаю»
- «Мне все равно»
- «Я могу с этим смириться»
- «Мне это не нравится»
Опросите достаточное число респондентов, чтобы получить статистически значимые результаты.
После проведения опроса наступает более сложный этап — интерпретация результатов.
Здесь существуют разные подходы.
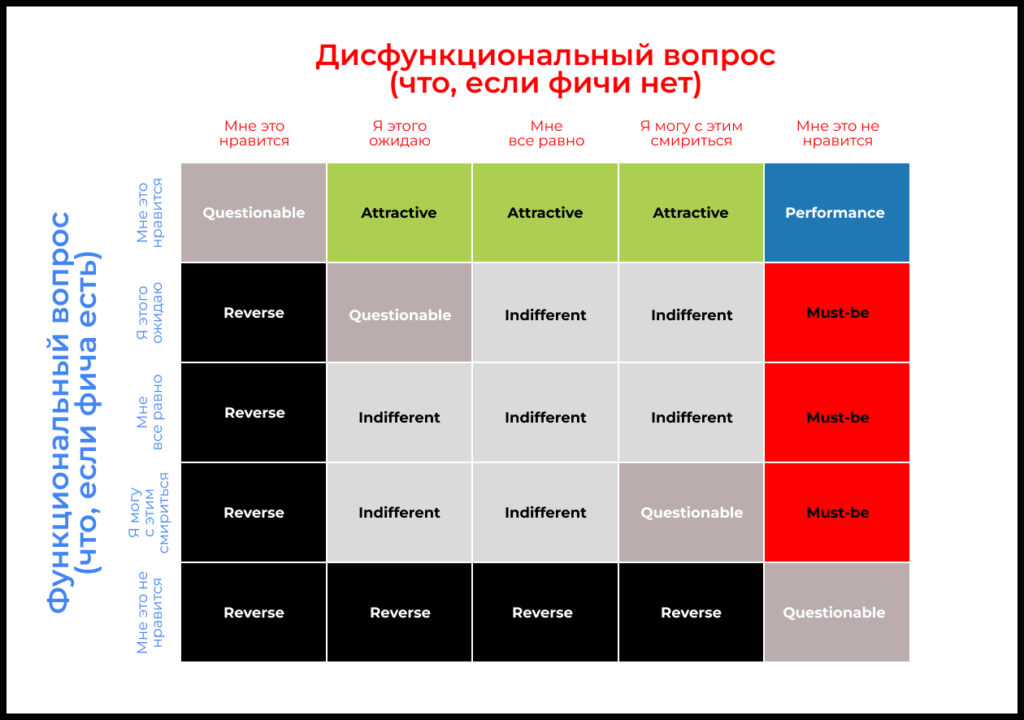
Логический квадрат
Самый простой путь интерпретации результатов опроса — проанализировать, сколько опрошенных относят фичу к той или иной группе. В этом может помочь логический квадрат — таблица, которая помогает классифицировать каждый ответ.
Ниже — пример такого квадрата.
- В столбцах указаны ответы на дисфункциональный вопрос (что будет, если фичи нет)
- В строках указаны ответы на функциональный (что будет, если она есть).
Каждая пара ответов соответствует одной ячейке таблицы.
Ваша задача:
- Распределить полученные ответы по логическому квадрату
- Затем свести распределение к процентному соотношению
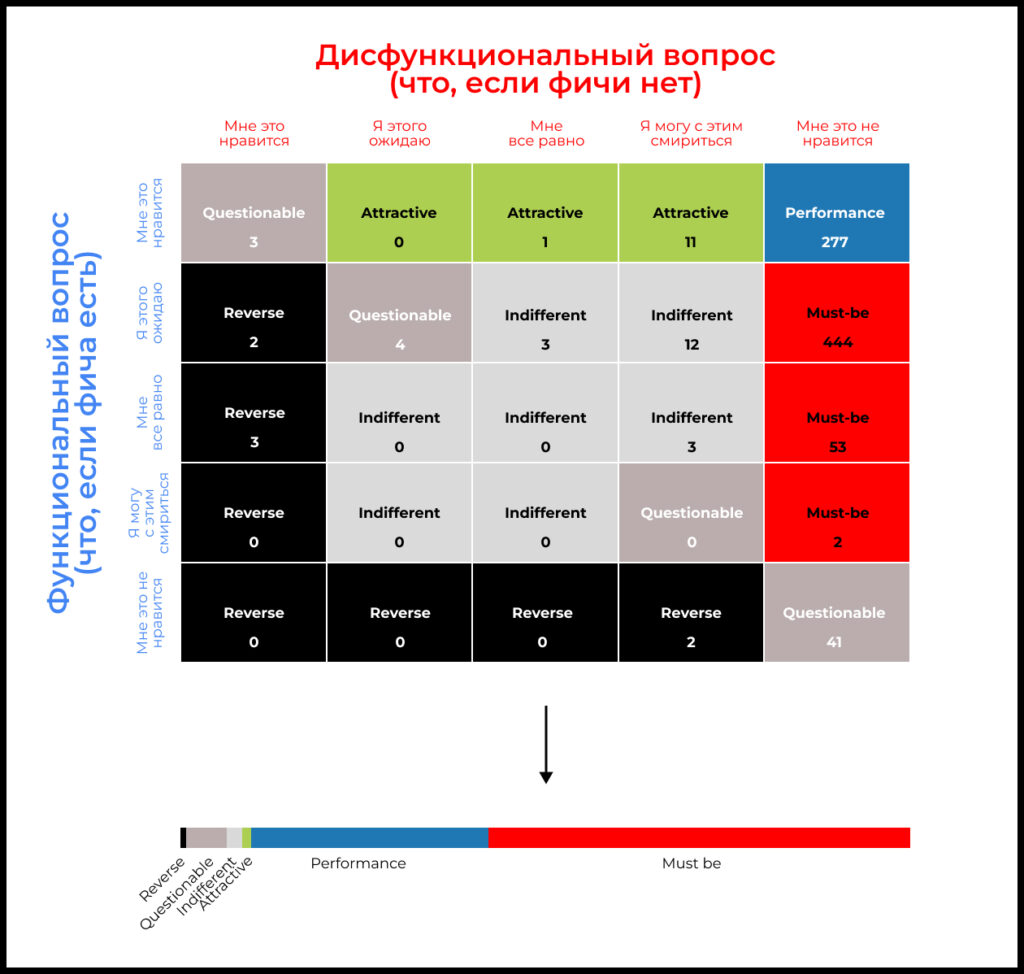
Повторите это упражнение для всех фич, которые хотите пропустить через процесс приоритизации.
Must-be и Performance фичи, которые набрали больше всего процентов, имеет смысл внедрять в первую очередь.
У этого метода интерпретации есть минус: многие фичи могут попасть в категорию Indifferent (дело в том, что люди склонны чаще давать средние оценки, чем крайние). Из-за этого может быть сложно принимать решения по фичам, которые вызывают умеренную реакцию.
Взвешенные оценки
Другой подход к интерпретации состоит в том, чтобы получить взвешенные оценки. Для этого используется система оценок баллами — от –2 до 4.
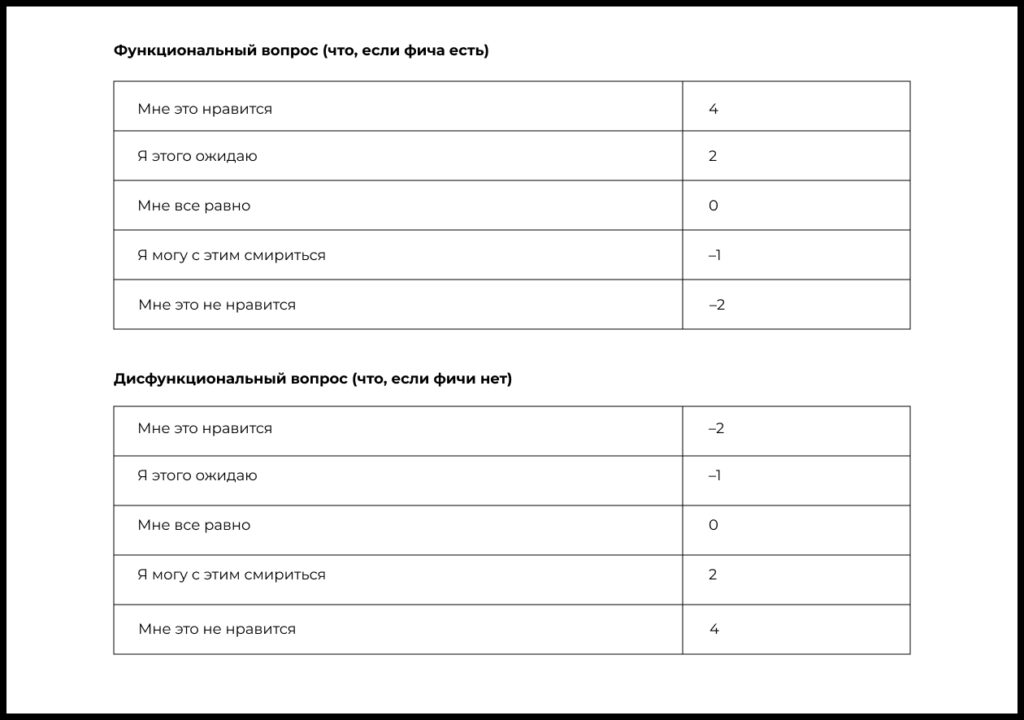
Теперь нужно подсчитать средние баллы:
- Берем все ответы на функциональный вопрос и рассчитываем средний балл → это будет координата по оси Y на плоскости координат
- Берем все ответы на дисфункциональный вопрос и рассчитываем средний балл → это будет координата X на плоскости координат

Такой подход позволяет:
- Снизить искажения из-за «средних» ответов, которые часто попадают в категорию Indifferent
- Сравнивать фичи между собой более точно (даже если они формально попадают в одну категорию
- Более наглядно увидеть приоритеты — особенно полезно, если у вас много фич и хочется точнее их рассортировать
Лучше/хуже
Еще один способ интерпретации результатов опроса — интегрированный метод «лучше/хуже», который позволяет дать оценку потенциальным изменениям в продукте следующим образом.
Сначала необходимо построить логический квадрат и свести распределение ответов к процентному соотношению, как мы уже обсуждали выше.
После этого (это важно!) мы перестаем учитывать в интерпретации значения, полученные для Questionable и Reverse, а оперируем только оставшимися категориями: Must-be, Performance, Attractive, Indifferent.
- Чтобы узнать, насколько продукт будет «лучше» в результате внедрения фичи, мы делим сумму Performance + Attractive на сумму всех категорий — Must-be + Performance + Attractive + Indifferent
- Чтобы узнать, насколько продукт будет «хуже» в результате отсутствия фичи, мы делим сумму Must-be + Performance на сумму всех категорий — Must-be + Performance + Attractive + Indifferent, а затем умножаем результат на –1, чтобы получить отрицательное значение
Это может быть не вполне очевидно, поэтому уточним, что:
- Под «суммой» имеется в виду сумма долей ответов, подсчитанная по итогам работы с логическим квадратом, а не сумма ответов как таковых
- Кроме того, сумма Must-be + Performance + Attractive + Indifferent не обязательно равна 100%, так как мы вычли из нее неучитываемые теперь Questionable и Reverse

Затем полученные значения для ряда фичей мы можем визуализировать в виде подобного графика:
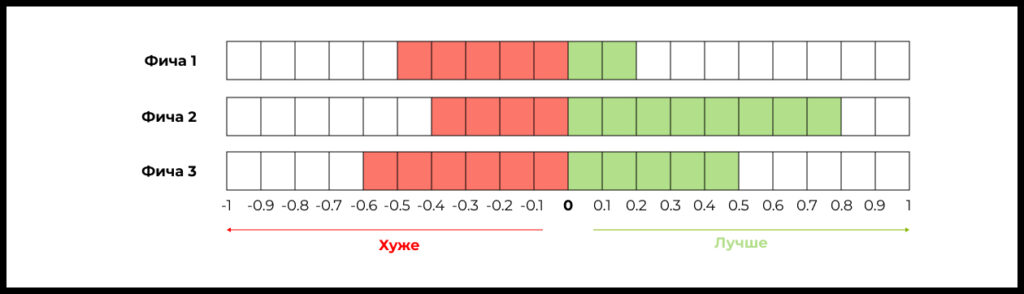
Полученные оценки позволят понять, за какие фичи стоит браться в первую очередь.
Дополнительное изучение
Если вы хотите углубиться в подробное изучение корней метода, то для начала можно прочитать оригинальную статью Нориаки Кано , а после — статью .
Также хорошим русскоязычным источником информации будет .
Понятная инструкция, как работать с моделью, есть в , там же можно найти готовый шаблон, чтобы ее построить.