
Летом 2022 года мы запустили «Симулятор SQL для продуктовой аналитики».
В этом материале авторы симулятора — Евгений Жульков, Олег Якубенков и Осман Рамазанов — рассказывают, почему решили создать отдельный курс по SQL для тех, кто вовлечен в работу над продуктом и маркетингом, и что было самым сложным в построении такого продукта с нуля.
Как возникла идея
Три года назад нашим первым и единственным образовательным продуктом был «Симулятор управления продуктом на основе данных», который обучал управлению продуктом на раннем этапе — от идеи к достижению product/market fit.
Симулятор решал не только образовательную задачу, но и объединял студентов в продуктовое сообщество, для которого мы стремились создать еще больше ценности. Так возникла мысль о создании других образовательных продуктов. Но прежде, чем переходить к реализации, нам нужно было понять, какие именно профессиональные темы больше всего востребованы нашими студентами.
Оказалось, что наиболее высокий спрос был у Python и SQL, а также темы управления ростом продукта (о ней мы поговорим позже).
Проблема с обучением Python заключалась в том, что интерес к теме был в большей степени обусловлен хайпом. Python — язык программирования в мире. Но, на наш взгляд, в продуктовой работе он востребован гораздо меньше, чем например, SQL.
С SQL ситуация иная: его незнание действительно снижает эффективность тех, кто работает над продуктом или маркетингом, потому что они вынуждены постоянно обращаться к аналитикам даже по простым запросам. Это отнимает время у всех участников процесса.
Прочитайте также наш материал о том, почему владение SQL — это важный навык для продакт-менеджера. В нем мы попросили опытных продакт-менеджеров поделиться своим опытом практического применения SQL в работе.
Даже те, кто владеет SQL на базовом уровне, часто не могут применить его в работе — не хватает навыков, чтобы переложить имеющиеся знания на реальные продуктовые задачи.
Поэтому уже на этапе проработки идеи мы договорились, что не будем делать курс с выдуманными абстрактными задачами, а сосредоточимся на прикладных ситуациях, иллюстрирующих реальную работу над продуктом или маркетингом. Для этого мы взяли несколько десятков кейсов из общения со студентами, в которых им мог бы пригодиться SQL, а затем анализировали их, чтобы понять, стоит ли разбирать их в нашем симуляторе.
В ходе опроса мы узнали, с какими задачами люди обращаются за помощью к своим коллегам, какие аналитические инструменты хотели бы освоить и для каких задач использовать. Мы просили привести примеры реальных рабочих задач, с которыми наши студенты недавно сталкивались, и объяснить — как они решали их, не владея самостоятельно необходимыми навыками. Дальше мы оценивали каждый кейс, отбирали самые приоритетные и частотные задачи. Именно они легли в основу нашего образовательного продукта.
Многие существующие курсы учат лишь синтаксису, да и то на примерах, которые очень далеки от реальной продуктовой работы. В реальной работе для решения прикладных задач надо разбираться, где лежат данные, как именно они хранятся, какие есть в них особенности, как их очистить для расчетов. Знание синтаксиса — это лишь небольшой кусочек, необходимый для принятия решений. Но даже знание синтаксиса не означает, что человек сможет подсчитать Retention или LTV через SQL-запросы — нужно понимать, как именно эти метрики устроены и как построить их расчет.
Олег Якубенков
Это похоже на обучение вождению. Можно прекрасно изучить ПДД и безошибочно проходить все тесты, но без реального опыта за рулем научиться водить не получится.
Очень много данных
Ключевым элементом — и самой трудоемкой частью в создании симулятора — стал датасет, на основе которого будут обучаться студенты. Перебрав много разных вариантов, мы пришли к решению, что датасет маркетплейса лучше всего подойдет для иллюстрации популярных практических задач, которые мы собрали на прошлом этапе.
Такой датасет хорош, во-первых, за счет количества различных переменных внутри продукта: покупатели, продавцы, товары, категории. Это позволяет создать комплексную картину работы с реальным продуктом.
Во-вторых, маркетплейс дает наиболее широкий набор кейсов, которые можно решить как с точки зрения продукта, так и с точки зрения бизнеса в целом. Важную роль сыграл и опыт работы Олега в компании, развивающей международный маркетплейс.
На основе этого датасета студенты должны разобраться:
- Как и где лежат данные;
- Как их изучать;
- Как их чистить;
- Как проверять результаты;
- Как решить задачу с помощью подручных средств, даже если не получилось написать идеальный запрос;
- Как считать продуктовые метрики.
Вся работа над датасетом заняла несколько месяцев, а с учетом доработки данных — больше года. Каждая итерация для генерации данных занимала десятки часов, а учесть нужно было огромное количество факторов.
У нас есть маркетплейс, в него пришел пользователь. Какой у него источник трафика? Из какой он страны? Что и когда он купил, на какую сумму? Когда он возвращался в продукт? И так далее. И это лишь один пользователь, а их будут десятки тысяч.
Затем надо внести данные о продавцах, о товарах, когда они появились на площадке, кто их купил. Все эти данные должны быть реалистичными, отражать реальную работу крупного маркетплейса и быть взаимосвязанными — то есть если пользователь покупает товар, то значит этот товар должен быть в наличии у конкретного продавца в определенный момент. Важно было учитывать и наличие истории, внутренних взаимосвязей и логики в данных.
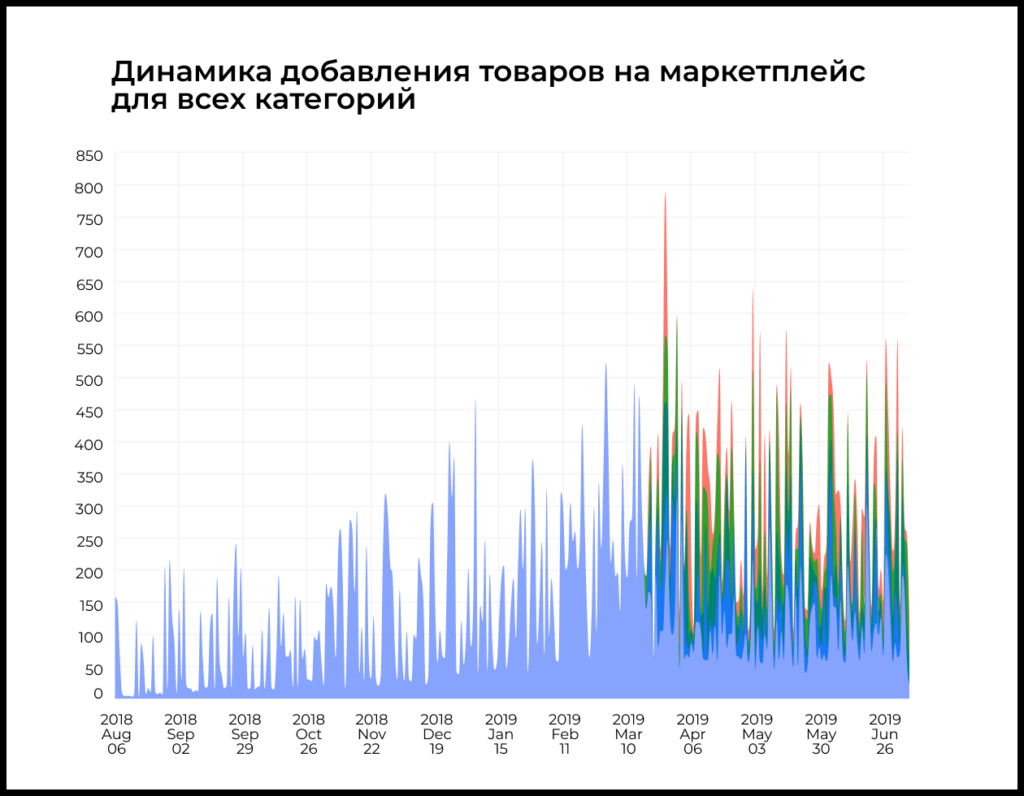
Дополнительно мы проработали сезонность, например как меняется Retention пользователей в зависимости от дня недели, месяца или сезона, учли, как меняется активность в покупателей в зависимости от времени суток.
Датасет намеренно приближен к реальному, поэтому в нем есть неточности, дубликаты данных, несуществующие пользователи и прочие баги, с которыми студентам нужно учиться разбираться. В реальной жизни маловероятно построить такую базу данных, в которой всего этого бы не было. Поэтому лучше научиться работать с такими данными на раннем этапе.
Как строили обучение
Самой сложной частью в создании симулятора стал дизайн глав: разложить комплексные темы и задачи на логичные составляющие, менять темп прохождения, чередовать сложные главы с простыми.
Темп заданий, сложность глав и само их содержание меняются на протяжении всего симулятора. Есть главы преимущественно объяснительные, есть сфокусированные на практике.
Сложность глав тоже меняется, и здесь можно провести аналогию с мобильными f2p-играми. В них сложность уровней чередуется: сначала простые, потом очень сложные, затем снова простые. Решение сложных задач помогает студенту испытать ощущение победы, а простые — помогают расслабить мозг и отдохнуть.
Евгений Жульков
Ключевым в дизайне глав было выстроить для студентов понимание того, как устроены таблицы и почему нужно использовать именно такой запрос, чтобы получить нужный результат.
Курс построен таким образом, что мы умышленно повышаем сложность заданий немного быстрее, чем даем студентам все новые инструменты для их решения. Это ведет к тому, что пользователи решают задачи с помощью старого инструментария, что может приводить к сложными, громоздкими и неэффективными решениям. Уже после этого мы мы рассказываем о новых конструкциях, которые позволяют решить задачу намного элегантнее. Цель в том, чтобы студент понимал, что любую задачу можно решать разными способами, но также начинал чувствовать на интуитивном уровне, зачем нужны те или иные функции или операторы.
Другим важным подходом стало то, что мы для многих заданий пошагово показываем, как конкретно запрос отрабатывает поверх таблицы. Это позволяет людям визуализировать процесс работы запросов и понять их намного лучше.
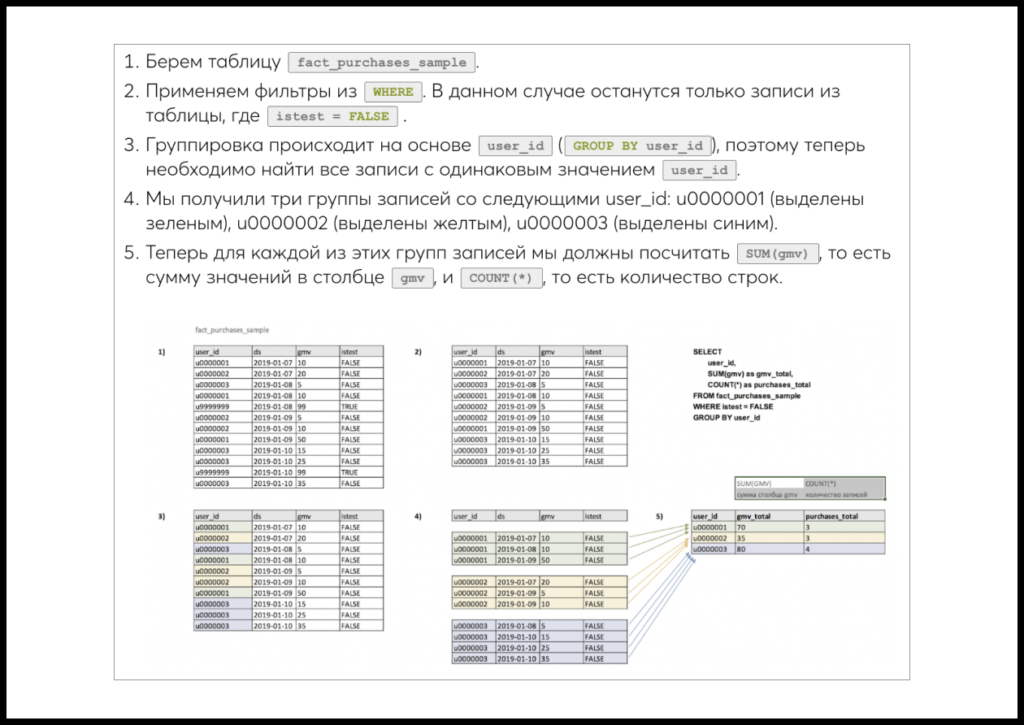
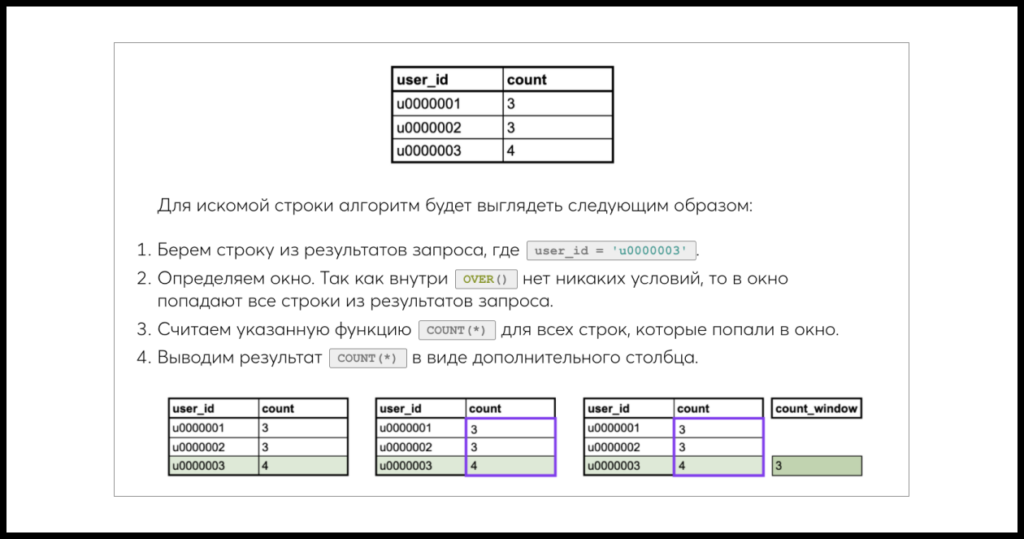
Первые версии симулятора мы обкатывали в Google Docs и Zeppelin с тестовыми группами. На этом уровне структура глав еще очень сильно менялась, а существенную часть образовательной работы выполняли мы сами.
По мере того, как мы понимали, как правильно доносить до студентов новые знания и навыки, симулятор начал приобретать все более устойчивую форму.
Как симулятор SQL стал частью симулятора роста — и обратно
Еще на этапе опроса, перед началом работы над SQL-симулятором, мы выяснили, что нашей аудитории интересна тема управления ростом и масштабирования продукта уже доказавшего свою ценность. И тема эта значительно сложнее и многообразнее, чем тема первого симулятора от GoPractice.
Потратив огромное количество сил и ресурсов на создание истории и датасета для SQL симулятора, мы решили объединить два направления работы и интегрировать накопленный для SQL-симулятора материал и личный опыт в то, что впоследствии стало «Симулятором управления ростом продукта».
Логика была такая: если в первом симуляторе сработало обучение управлению продуктом в комбинации с работой в аналитическом инструменте Amplitude, то во втором симуляторе тоже можно подключить инструмент для аналитики, в частности SQL, который студент изучает параллельно с теорией.
Попытка совместить обучение более сложному инструменту, чем Amplitude, и изучение самой темы управления ростом конфликтовали. Для части студентов SQL был неактуален: у senior-специалистов особой потребности в нем нет, либо они уже его знают. При этом изучение SQL занимало много времени, в итоге пропадал фокус с основных вещей, то есть темы роста продукта.
Разрешить этот конфликт в рамках одного продукта не получилось — он рассыпался, а пользователи указывали на низкое количество инсайтов на потраченное время.
Олег Якубенков
Стало понятно, что обучение SQL и обучение управлению ростом продукта — это две разные задачи, для разных сегментов аудитории. Поэтому «Симулятор SQL для продуктовой аналитики» стал самостоятельным продуктом.
При этом SQL по-прежнему выполняет в симуляторе роста важную роль, позволяя самостоятельно изучать данные в процессе прохождения. Но для тех, кому изучение или использование SQL неактуально или неинтересно, мы сделали задания с SQL опциональными — всегда можно воспользоваться уже готовым запросом, чтобы получить и изучить необходимые данные.
Понять, что симуляторы лучше развести как самостоятельные продукты, нам помог фидбек от тестовых когорт. Общение со студентами по итогам тестов позволило вычистить огромное количество мелких ошибок и переделать структуру симулятора, чтобы качественнее доносить знания и навыки до студентов.
Что есть в симуляторе, а чего нет — и почему
Целью нового симулятора было обучить SQL на уровне, который позволит решать типичные продуктовые задачи, связанные с продуктом или маркетингом. В этом помогли эксперты и фидбек студентов, которые сразу применяли знания на практике и делились новыми задачами. Так цикл повторялся несколько раз.
Наиболее частыми запросами, которые нашли отражение в симуляторе, стали:
- Задачи по подсчету кривой Retention
- Расчет верхнеуровневых метрик (DAU/WAU/MAU)
- Подсчет количества новых пользователей, продаж, прибыли
- Расчет LTV, сегментация или выгрузка пользователей по условиям
- Подсчет ROI для каналов привлечения и многие другие.
На основе фидбека мы также добавили задания на изучение . Это более продвинутый аналитический инструмент, который упрощает подсчет многих метрик. Он помогает с подсчетом скользящего среднего, нарастающих итогов, построением отчетов и многих других задач, где вам нужно сделать подсчет показателей над набором строк.
На основе отзывов студентов мы сформировали финальное задание — продуктовый кейс, в котором студент применяет все полученные знания об SQL. Решение позволит ответить на комплексный вопрос о влиянии изменений на продукт.
Осман Рамазанов
При этом мы намеренно отказались от некоторых тем, например манипуляции данными с использованием SQL: удаление, изменение или добавление данных, создание таблиц и так далее. Это важный пласт знания об SQL, но, на наш взгляд, он в гораздо меньшей степени актуален для продактов, маркетологов, а иногда и аналитиков, потому что за целостность данных в базе и минимизацию ручного вмешательства отвечают программисты.
Результат работы
По итогам разработки симулятора мы получили:
- Около 4,5 миллионов записей о пользователях маркетплейса;
- 130 тысяч записей о продавцах, которые сгенерировали 8 миллионов записей о товарах;
- Десятки миллионов записей о просмотрах и покупках товаров пользователями, и других данных;
- Общий размер смоделированной базы — 15 гигабайт.
Поделимся парой отзывов наших студентов о получившемся симуляторе:
Курс действительно является большим шагом для стирания барьера перед походом в «таблички» самостоятельно. Как обычно, очень порадовали живые примеры на протяжении всего обучения. Кейсы и задачи, представленные в заданиях, очень точно симулируют живые рабочие ситуации и направления исследований в компании. После прохождения курса складывается впечатление, что поработал аналитиком и готов к новым челенджам.
Дмитрий Алексеев, Product Manager, VK
SQL-симулятор, как и остальные продукты GoPractice, превзошел ожидания. Я получила возможность за месяц пройти путь от написания самых элементарных запросов до работы с оконными функциями и получения ответов на продуктовые вопросы, с которыми бизнес сталкивается на ежедневной основе. Я лично не буду писать запросы каждый день, но курс однозначно дал мне хорошую базу по SQL, позволил стать ближе в коммуникации с аналитиками, более качественно подходить к подбору кандидатов и иметь возможность ответить на ряд продуктовых вопросов, когда нет времени ждать. Однозначно рекомендую курс к прохождению всем продуктовым менеджерам, которые работают на продуктах с серверной аналитикой!
Елена Бахнева, CEO, JatApp