
«Паника, которую вызывает AI всякий раз, когда делает что-то новое, постоянно сводится к одному и тому же. Мы задаем рамку, наблюдаем, как модели ее осваивают, а затем начинаем путать саму рамку с тем, что она описывает».
В этом материале глава Every Дэн Шиппер делится размышлениями о том, почему спрос на экспертов в действительности не снижается, а только возрастает по мере развития AI-моделей и повышения их эффективности решения сложных задач. Мы подготовили адаптированный перевод.
Это объемный и глубокий материал, мы рекомендуем выделить время для его изучения. Он того стоит.
Оригинал можно прочитать .
Парадокс
В основе AI скрывается парадокс.
В Every мы автоматизировали все, что могли. Мы используем Codex и Claude Code для программирования, написания текстов, дизайна, клиентской поддержки и множества других задач. Мы тестируем новые модели OpenAI, Anthropic и Google еще до их официального релиза. Мы стараемся максимально быстро и эффективно использовать экспоненциальный рост возможностей моделей и автоматизации.
И все же кажется, что работы, выполняемой людьми, у нас стало больше, чем когда-либо. В нашей команде почти 30 человек — и мы не уволили сотрудников в пользу агентов. Мы не отказались от SaaS-сервисов в пользу приложений, написанных с помощью вайбкодинга. Мы по-прежнему нанимаем людей для обслуживания клиентов — хотя и во многом с помощью агентов. Мы по-прежнему нанимаем авторов, редакторов и инженеров.
При этом сама работа выглядит совершенно иначе, чем раньше. Мы больше не пишем код вручную. Если вы упомянете кого-то через @ в нашем Slack, то не всегда понятно, разговариваете вы с человеком или с агентом. Руководители пишут код наравне с разработчиками, а инженеры напрямую общаются с клиентами. Уже несколько недель AI отвечает на 95% моих рабочих писем. Входящие у меня почти всегда разобраны до нуля (для меня это редкость), хотя я все равно просматриваю почту лично.
Короче говоря, будущее выглядит одновременно странным и в то же время знакомым. И это ощущение удивительно. Если уж в чем-то руководители, специалисты и инвесторы сходятся во мнении, так это в том, что AI представляет угрозу для рабочих мест, экономики, безопасности и даже смысла жизни людей.
Генеральный директор Anthropic Дарио Амодеи предупреждает, что AI может уничтожить до половины всех рабочих мест начального уровня у белых воротничков. Компания Марка Цукерберга недавно 8 тысяч сотрудников и устанавливает на компьютеры сотрудников в США софт, который отслеживает движения мыши, клики и нажатия клавиш. Идея в том, чтобы собирать более качественные данные для обучения AI в области сложных интеллектуальных задач.
Даже Кен Гриффин из Citadel, похоже, тревогу. Недавно он заявил: «Речь идет не о каких-то средних офисных профессиях. Мы говорим о чрезвычайно высококвалифицированной работе, которая — подберу подходящее слово — автоматизируется агентным AI».
Результаты тестов, которые с каждой новой моделью растут почти экспоненциально, похоже, подтверждают это. В тесте «» — тесте, который проверяет уровень логического мышления — лучшие модели за год поднялись с единичных процентов до примерно 44%.
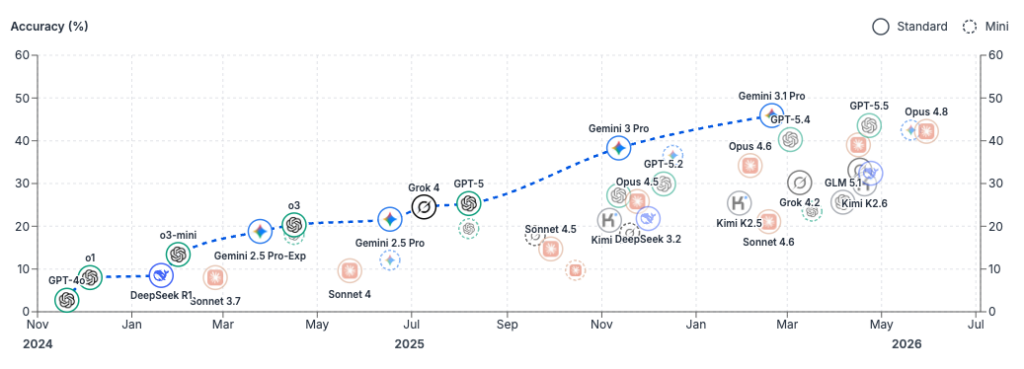
На — тесте, который проверяет, насколько хорошо перспективные модели справляются с реальной экономической работой по сравнению с людьми — показатели подскочили с аналогично низких показателей до примерно 85%. В мае организация METR (она исследует безопасность AI) ранние результаты Claude Mythos: модель успешно справилась с 80% задач, на которые эксперту-человеку потребовалось бы около четырех часов работы.
Похоже, мы стоим на пороге появления AI, который будет умнее любого человека и сможет автономно работать почти целый день подряд.
И все же парадокс остается. Если поговорить с людьми из AI-индустрии — или просто с теми, кто начал пользоваться этими инструментами раньше других, — вы услышите то же самое, что наблюдаем и мы внутри компании: работы становится не меньше, а больше.
Главный вопрос (как внутри индустрии, так и за ее пределами) заключается в следующем — это временное положение дел? Заменит ли следующая модель всех? Мы следим за бенчмарками и нервничаем, гадая, не приближается ли переломный момент, когда все рабочие места исчезнут.
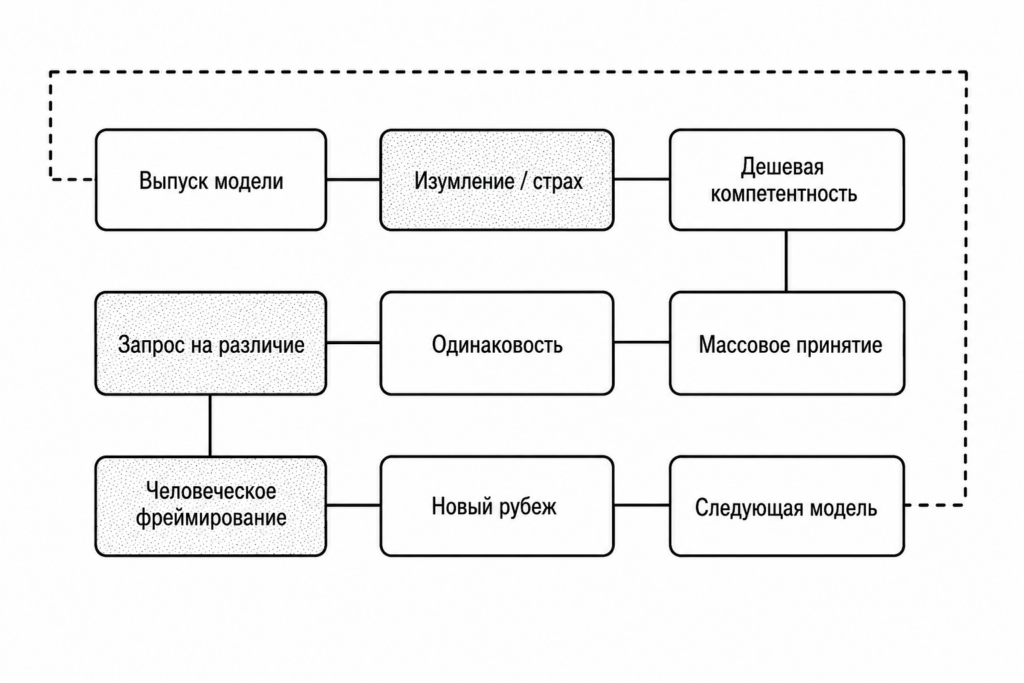
Но никакого переломного момента, который перевернет все с ног на голову, не будет. Новая реальность прямо противоположна: чем больше мы автоматизируем, тем больше появляется работы, требующей экспертных знаний.
Причина проста. AI превращает в товар остатки человеческой экспертизы — все, что можно достаточно четко описать и использовать для обучения модели. Это создает спрос на то, что отличается от стандартного результата. В частности спрос на экспертов-людей — даже в момент, когда мы приближаемся к AGI.
Чтобы понять почему так происходит, нужно выйти за пределы графиков и посмотреть, как AI используется в работе прямо сейчас. Тогда можно по-настоящему разобраться и в самом парадоксе, и в том, как его разрешить.
Как мы тут оказались
Три года назад я написал (allocation economy). Ее основная идея — в том, что работа с AI-инструментами со временем станет похожа на работу менеджеров-людей. Это было тогда, когда даже обычное взаимодействие с ChatGPT в формате промпт–ответ казалось чем-то почти фантастическим.
Затем, в середине 2025-го, наша компания буквально подсела на Claude Code. Киран Клаассен, генеральный менеджер , внезапно обнаружил, что может отказаться от ручного написания кода и вместо этого целыми днями давать агенту-программисту инструкции на обыкновенном английском языке прямо в терминале. Очень быстро этот подход распространился на всю компанию.
Я упоминаю об этом, потому что наши самые удачные прогнозы были сделаны благодаря тому, что мы рассматривали Every как своего рода лабораторию для ранних пользователей. Обычно мы сталкиваемся с новыми рабочими практиками задолго до того, как они становятся общепринятыми. А затем, по мере развития технологий и упрощения использования инструментов, эти практики начинают распространяться по всему рынку.
Вот что происходит сейчас внутри компании.
Два режима работы с агентами
Работа с AI постепенно делится на два совершенно разных режима.
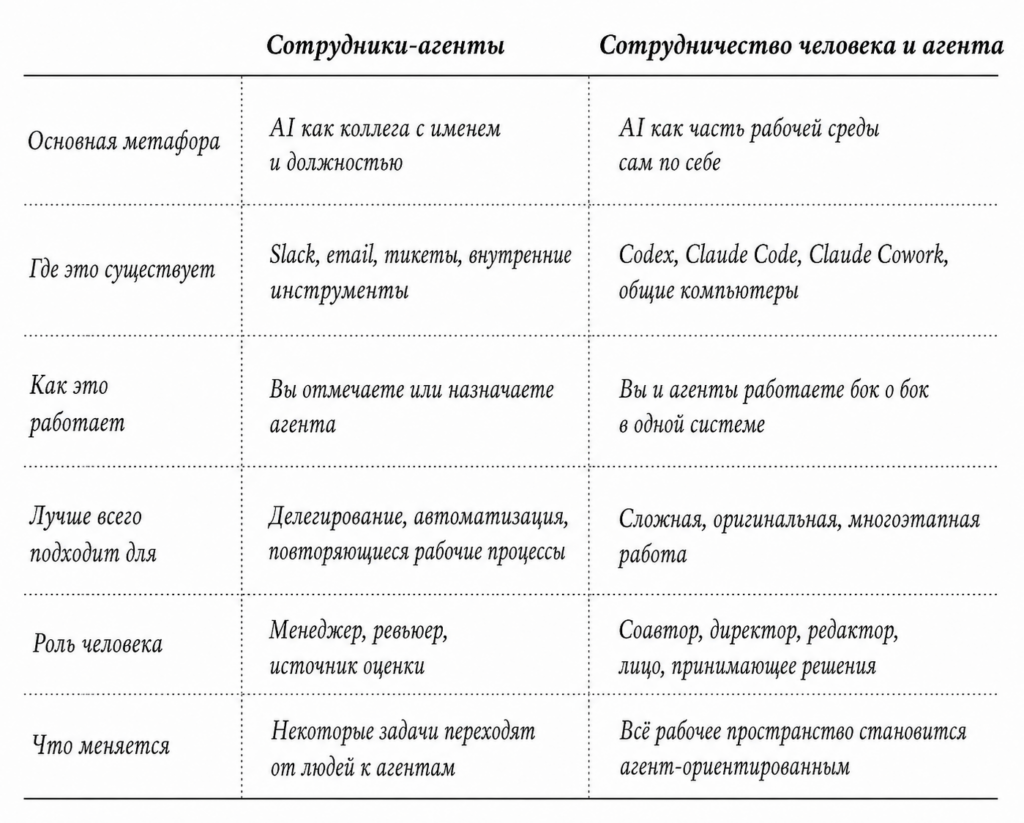
Первый — тот, появления которого довольно точно предсказывали: агенты как сотрудники. Это агенты, которым можно делегировать работу. Одни живут в Slack, имеют собственные имена и должности, и их можно упомянуть, когда нужно что-то сделать. Другие встроены в постоянные рабочие процессы — например, в клиентскую поддержку — и выступают в роли постоянных исполнителей рутинных задач.
Второй режим более странный и, по моему опыту, более важный. Речь о совместной работе человека и агента в таких инструментах, как Codex, Claude Code и Claude Cowork. Это уже не просто места, где можно передать задачу. Но скорее операционные системы для самой работы, где вы и несколько агентов одновременно используете один и тот же компьютер для решения сложных, оригинальных задач, которые не может выполнить асинхронный агент.
В обоих режимах AI позволяет автоматизировать и делегировать значительную часть работы. И в обоих случаях для хорошего результата по-прежнему нужен человек.
Агенты-сотрудники
Агенту-сотруднику ставят задачу, и после этого он сам выполняет ее: составляет отчет, пишет черновик или принимает решение по приоритетам — без вашего участия. Такие агенты бывают как минимум двух типов: агенты-коллеги и встроенные агенты.
Агенты-коллеги
Агент-коллега — тот, кого можно, например, упомянуть в Slack и попросить выполнить работу. Он всегда рядом, когда вам это нужно. К этому типу относятся агенты вроде OpenClaw или нашего внутреннего агента .
Клоди
Клоди — агент консалтинговой команды. Он пишет коммерческие предложения, готовит черновики обучающих презентаций, следит за списками задач по проектам и занимается многими другими вещами.
Энди
Энди — агент редакционной команды. Он собирает «жемчужины» — интересные идеи для материалов из внутренних обсуждений в Slack — и превращает их в дайджесты и первые наброски, которые наши авторы затем используют при подготовке ежедневной рассылки.
Виктор
Виктор — универсальный агент, который помогает всей организации. Мы используем его для сбора метрик роста, анализа пользовательских опросов и преобразования хаотичных внутренних обсуждений в исследовательские заметки и продуктовые рекомендации.

Встроенные агенты
Встроенные агенты работают внутри конкретного продукта или бизнес-процесса. Они менее гибкие, чем агенты-коллеги, но могут быть очень полезны для выполнения повторяющихся задач.
Наглядный пример — Фин, агент, встроенный в нашу систему клиентской поддержки. Он берет на себя значительную часть обращений пользователей через чат и электронную почту.
За одну из недель мая Фин участвовал в 65% из 202 обращений в службу поддержки Every и самостоятельно закрыл 81 из них. Это 40,1% всех обращений, по которым требовалось какое-либо действие.
Подобные встроенные агенты позволяют нашему менеджеру по обслуживанию клиентов тратить меньше времени на ответы по типовым запросам и больше — на развитие самой системы поддержки и решение сложных случаев, где требуется более внимательное взаимодействие с клиентом.
Совместная работа человека и AI
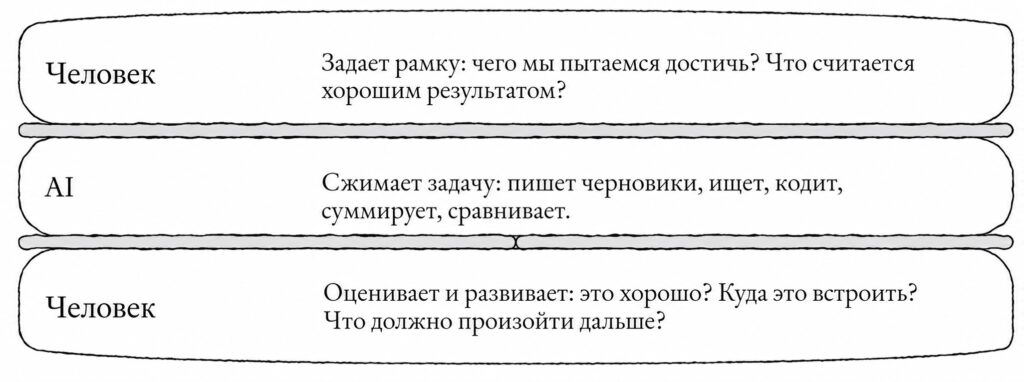
И в случае агентов-коллег, и в случае встроенных агентов есть одна и та же закономерность. Агенты берут на себя все больше стабильной, повторяемой и хорошо структурированной работы. Но остается много работы, для которой по-прежнему нужен человек. Мы снова и снова убеждаемся, что для любой по-настоящему сложной задачи лучший результат получается тогда, когда AI и человек работают вместе в одном рабочем пространстве, постоянно взаимодействуя друг с другом.
Именно для этого существуют Codex, Claude Code и Cowork. Они позволяют запускать одного или нескольких агентов и делегировать им задачи через несколько параллельных диалогов. Эти агенты имеют доступ к вашему компьютеру и всем вашим источникам данных. Вы видите каждую задачу, над которой работает агент, можете наблюдать за ходом его рассуждений и в любой момент вмешаться.
При этом именно человек отвечает за управление агентами в начале и в конце каждой задачи: он определяет направление работы, проверяет качество результата и решает, чем заниматься дальше. Киран Клаасен называет это «»: мы выступаем в роли двух ломтиков хлеба по обе стороны работы AI.
Самый очевидный пример — программирование. Инженеры Every проводят весь день обмениваясь информацией с агентами. Они планируют новые функции и исправления ошибок, проверяют уже выполненную работу и — если следуют нашей философии комплексного проектирования () — постепенно улучшают собственную систему разработки.
Но подобное сотрудничество выходит далеко за рамки программирования.
Новая операционная система для интеллектуального труда
Codex и Claude Code постепенно становятся новой операционной системой для работы. Почти весь день я провожу в Codex, используя свои SaaS-инструменты через встроенный браузер. Это позволяет мне использовать своего агента во всем, что я делаю, и работать на уровне, которого я не смог бы достичь в одиночку.
Написание текстов
Этот текст я пишу в нашем редакторе для совместной работы людей и агентов через встроенный браузер Codex. Codex наблюдает за тем, что я пишу, и может в любой момент запустить отдельного агента для выполнения нужной задачи: написать черновик абзаца, найти примеры для следующего раздела или отредактировать текст.
Электронная почта
Точно так же я работаю с почтой. Мой почтовый клиент — Cora, и я запускаю его внутри встроенного браузера Codex. Я просматриваю входящие письма и вслух обсуждаю каждое из них с . Остальное берут на себя Codex и Cora.
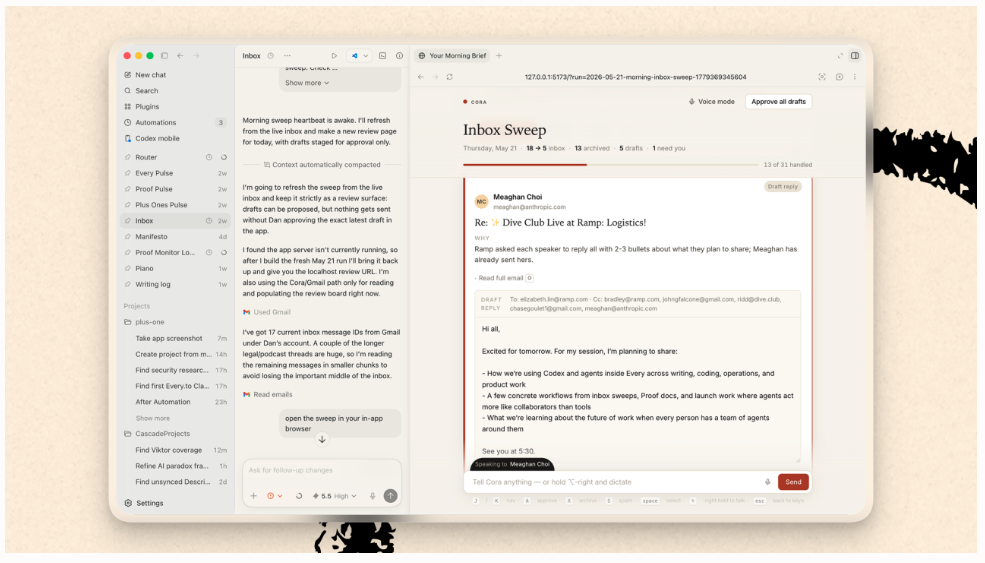
Каждому агенту нужен человек
Наверное, вы уже заметили, где во всей этой автоматизации определено место для человека. Во всех приведенных примерах агенту нужен человек, чтобы работа вообще выполнялась.
Кто-то должен поставить агенту правильную задачу, решить, хорош ли полученный результат, заметить ошибки и превратить вывод модели в реальное решение или рабочий процесс.
Чем дальше агент оказывается от человека, который отвечает за качество его работы, тем хуже он работает. Когда мы только начали внедрять агентов-сотрудников внутри компании, у каждого сотрудника собственный агент. Но довольно быстро мы к модели, где агенты работают на конкретную команду или на всю компанию, а не на отдельных людей.
Почему? Потому что агенты требуют поддержки. Персональные агенты быстро устаревали, когда сотрудники переставали активно ими пользоваться. Сейчас у нас есть команда AI-инженеров, которая отвечает за качество работы агентов. И, по всей видимости, она понадобится нам еще очень долго. Даже сравнительно простая задача вроде автоматической подготовки презентаций PowerPoint может оказаться сложной. Одна из наших автоматизаций для создания презентаций включает 24 отдельных навыка и 18 скриптов и тратит токены примерно на 62 доллара для подготовки одной пачки слайдов.
Это главная причина, по которой агенты создают для людей больше работы.
Но есть и другая причина.
***
***
Почему автоматизация создает больше работы для людей
Если посмотреть на экспоненциальную траекторию развития AI за последние несколько лет и задуматься, как устроены современные модели, можно увидеть несколько устойчивых механизмов обратной связи, которые, вопреки ожиданиям, создают больше работы для людей.
AI делает человеческие компетенции дешевле
Современные языковые модели обучаются на том, что делал человек: коде, текстах, изображениях, тикетах поддержки, продуктовых спецификациях и многом другом. Они берут весь этот материал — побочный продукт уже выполненной работы — и упаковывают его в форму, доступную практически каждому и по очень низкой цене.
В результате навыки, которые раньше были редкими и ценными, — например, написать pull request, сделать превью для YouTube или подготовить рассылку, — становятся доступны почти любому человеку.
Недорогие компетенции быстро внедряются
Когда стоимость чего-то ранее редкого резко падает, предложение столь же резко растет. В Every мы видим это постоянно. Сотрудники операционных и клиентских команд пишут код и создают pull requests. Маркетологи делают превью для YouTube. Инженеры и продакт-менеджеры пишут черновики статей, гайдов и лендингов — хотя раньше никогда бы этим не занимались.
То же самое происходит и за пределами Every. Возьмем, например, OpenClaw — open-source проект AI-агентов. По состоянию на 16 мая 2026 года в его репозитории уже было создано 44 469 pull requests, из которых 12 430 появились после 1 апреля и 3 990 — после 1 мая. Это колоссальный объем работы. Для сравнения: Kubernetes — один из самых популярных open-source проектов в мире — получил около 5 200 pull requests за весь 2022 год.
Изобилие порождает однообразие — старая экспертиза превращается в товар
Поскольку все пользуются одними и теми же моделями, а сами модели основаны на вчерашних человеческих компетенциях, по умолчанию они производят результат, который колеблется между «неплохим стартом» и откровенной халтурой — AI-слопом.
Слоп— это не какая-то конкретная ошибка. Это не длинные тире, не определенный ритм предложений и не фиолетовые акценты на лендинге. Скорее это заметное однообразие, повторяющееся снова и снова.
Такой результат возникает естественным образом, когда множество людей в разных ситуациях используют один и тот же инструмент, обученный на одном и том же корпусе данных, не задумываясь слишком глубоко о том, что делают. Это происходит, когда у всех появляется доступ к одному и тому же «эксперту» с одинаковыми базовыми склонностями.
Когда сотрудник операционной команды может создавать pull requests, маркетолог — за секунды генерировать превью для YouTube, а инженер — писать продуктовые гайды, легко оказаться в мире, где объем выпускаемой работы вырос, а вот ее качество, целостность и уникальность снизились.
Изобилие однообразного контента очень быстро превращает его в обычный товар.
Однообразие создает спрос на отличие
Люди быстро учатся распознавать слоп — во многом благодаря интернету. Любая работа может мгновенно оказаться перед глазами миллионов других людей. И когда слишком многое начинает выглядеть одинаково, мы чувствуем подвох.
Поэтому первое знакомство с новой моделью обычно производит сильное впечатление — и даже немного пугает. Но проходит несколько месяцев, и ее способности начинают казаться чем-то обыденным. Просто потому, что ваши стандарты уже изменились.
Нам нужны не просто React-приложения или исследовательские отчеты. Нам нужно, чтобы они идеально подходили конкретному человеку, компании и ситуации. Мы хотим получить нечто живое и уникальное, а не дешевое и универсальное. Мы хотим то, что требует больше времени или денег на создание, чем нам требуется на потребление этого результата.
Мы хотим то, что обладает статусом. И всякий раз, когда новая технология делает прежний статус дешевым, люди очень быстро придумывают новые правила этой статусной игры.
Когда работа везде выглядит одинаково, именно то, что выбивается из шаблона, превращается в редкий, ценный и статусный ресурс.
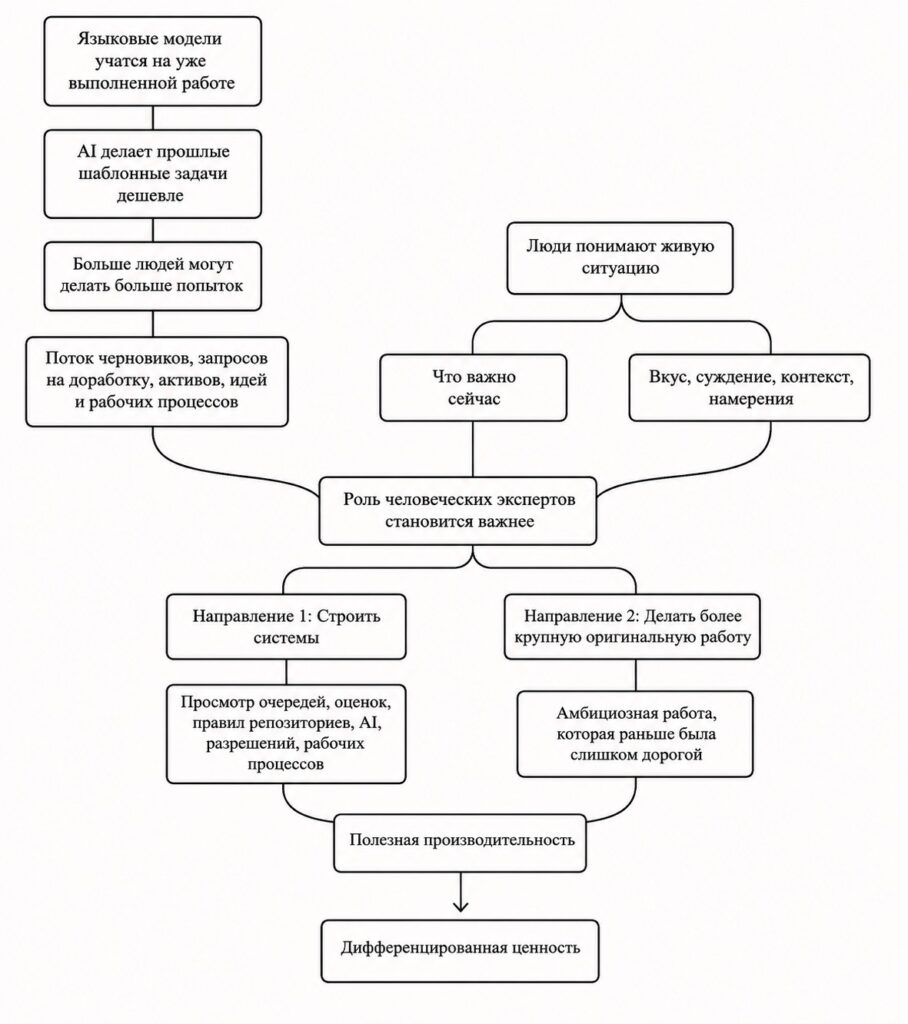
Спрос на отличие создает новый спрос на экспертов
Из-за архитектуры языковых моделей и того факта, что они доступны всему миру, по-настоящему редкая и ценная работа должна исходить от человека. Нынешнее поколение моделей знает только о том, что уже было сделано. Люди же знают, что нужно сделать прямо сейчас.
Как только конкретная ситуация превращается в текст и попадает в обучающий датасет, она становится частью прошлого. Люди же находятся внутри текущего момента — с конкретным клиентом, конкретной кодовой базой, конкретным разговором. Данные, на основе которых обучается модель, такого дать ей не могут.
Но дело не только в более свежих данных. Каждый человек приходит в ситуацию с какой-то своей перспективой — своей историей, своими желаниями, тревогами, интересами и пониманием того, что сейчас важно. Именно это влияет на то, что он замечает и как интерпретирует происходящее. Модель может воспроизвести такую перспективу после того, как ей ее задали. Но не до этого. Именно здесь проявляется парадокс, с которого началась статья.
Удешевление экспертной работы не может просто заменить экспертов. Оно создает больше ситуаций, в которых экспертное суждение становится необходимым.
Когда сотрудники операционных команд начинают создавать pull requests при помощи AI, нужны инженеры, которые будут их проверять. Когда маркетологи массово генерируют превью для YouTube, нужны дизайнеры, которые доведут их до ума. Когда инженеры начинают писать тексты, нужны редакторы и авторы, которые сделают эти тексты действительно хорошими.
В ответ эксперты начинают двигаться сразу в двух направлениях.
- Одни используют AI для создания систем, способных переваривать и направлять поток новой работы: очереди проверки, оценки, тестовые среды, правила репозитория, файлы инструкций Claude и Codex, непрерывная интеграция (CI), разрешения и рабочие процессы, которые превращают первые попытки в хорошие результаты.
- Другие используют AI для выполнения задач, которые раньше были им недоступны. Например, поиск уязвимостей в операционных системах, таких как macOS, обычно занимает недели или месяцы. Небольшая компания по кибербезопасности Calif использовала Anthropic Mythos Preview и первую общедоступную уязвимость памяти ядра macOS на оборудовании Apple M5 всего за пять дней.
Именно поэтому на практике AI не устраняет потребность в экспертной интеллектуальной работе. Он резко увеличивает объем создаваемой работы, но эта работа не становится ни ценной, ни отличимой от слопа без участия человека.
Конечно, не факт, что AI обязательно создаст больше работы для всех профессий. Экономика слишком сложна для таких выводов. Но независимо от вашей текущей профессии всегда будет форма работы, которая структурно остается на шаг впереди моделей. Это работа по использованию самих моделей для решения сегодняшних задач в сегодняшнем контексте. Именно в эту сторону движется интеллектуальный труд.
Но как быть с экспоненциальным ростом результатов на бенчмарках?
Здесь возникает очевидное возражение. Достаточно посмотреть на экспоненциальный рост результатов AI в различных тестах, чтобы предположить: все описанное выше носит временный характер. Нужно лишь подождать, пока модели догонят людей.
Но здесь есть ловушка. Это chart psychosis — «психоз графиков». Если постоянно смотреть на графики METR, читать прогнозы вроде и строить представление о будущем исключительно на основе экстраполяции вычислительных мощностей и результатов бенчмарков, легко прийти к весьма тревожным выводам о том, что означает прогресс моделей.
Лучший способ разобраться в этом — не просто рассуждать о гипотетических будущих моделях, а понять, как вообще устроены бенчмарки и что именно они измеряют.
Вот конкретный пример.
Как создаются бенчмарки
В Every существует собственный внутренний тест под названием Senior Engineer Benchmark. Как следует из названия, он предназначен для оценки того, насколько хорошо современные модели справляются с задачами уровня старшего инженера — например, с крупным рефакторингом программной системы.
В рамках этого теста агент получает реальную производственную кодовую базу Proof, которую автор когда-то собрал с помощью вайбкодинга, а затем передал старшему инженеру для правок.
Агенту показывают состояние проекта до исправления и дают инструкцию, похожую на ту, которую можно было бы дать опытному инженеру: «Этот код представляет собой вайбкодинговый слоп. Перепиши его заново, исходя из метода первых принципов».
Это хороший бенчмарк. Он требует от агента самостоятельно разобраться во множестве разрозненных проблем, понять их общую причину и провести полноценную переработку системы. Для сравнения я также использую две версии рефакторинга, выполненные реальными senior-инженерами с использованием AI, и применяю их для оценки результатов моделей.
Большинству кодовых агентов такая задача дается тяжело.
Модель должна не только обнаружить корень проблемы, но и удерживать его в памяти на протяжении многих шагов работы, не отвлекаясь на детали существующего кода. Кроме того, ей нужно быть готовой удалять большие фрагменты системы, а именно этого агенты обычно стараются избегать.
Большинство моделей способны понять направление рефакторинга, но в итоге предпочитают латать дыры поверх существующей архитектуры вместо того, чтобы действительно устранять проблемы.
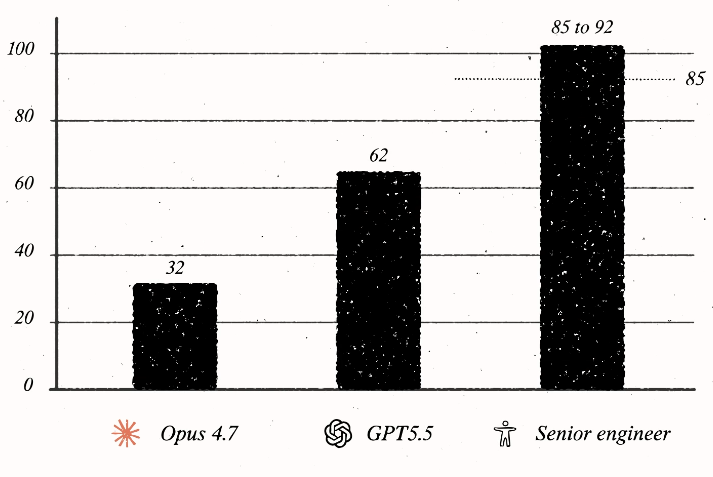
Ситуация изменилась с появлением GPT-5.5.
На лучшем запуске модель получила 62 балла из 100 — примерно на 30 баллов больше, чем Opus 4.7. Это важный рубеж. Модель уже выглядела не как автодополнение, не как помощник и не как инструмент, а как нечто неприятно близкое к человеку. Для сравнения: настоящий senior-инженер обычно набирает на этом тесте от высоких 80 до низких 90 баллов. То есть до человеческого уровня остается примерно 30 баллов.
Модели вполне могут выйти на уровень 80–90 баллов по этому тесту уже в течение следующего года. Но здесь важно понимать, что именно измеряет такой результат. Потому что оценка 62 — это не просто оценка модели. Это оценка модели внутри определенной рамки.
Бенчмарки измеряют работу внутри рамки
Чтобы создать бенчмарк для модели, сначала нужен промпт. Без него модель представляет собой просто инертное множество почти бесконечных возможностей.
Промпт создает небольшой мир — набор вещей, которые имеют значение, и способов их интерпретации. Он сужает пространство возможностей до конкретной траектории, по которой начинает двигаться модель. Поведение модели «само по себе» — не слишком осмысленное понятие. Мы можем наблюдать только то, как она реагирует на разные промпты.
После того как промпт задан, модель на короткое время словно оживает, сводя это инертное множество возможностей к одному конкретному предположению о том, что должно последовать дальше.
В Senior Engineer Benchmark мы просим модель исправить кодовую базу и затем самостоятельно проверить результат своей работы. Если в тестовой среде нет встроенной функции постановки цели, мы дополнительно запускаем автоматического «бэбиситтера», который подталкивает модель, когда она останавливается, и спрашивает, закончила ли она то, что собиралась сделать.
В качестве исходной рамки мы используем на первый взгляд довольно простой промпт. Он специально написан так, как его мог бы написать обычный вайбкодер. В нем нет большого количества технических терминов, и он не содержит очевидного ответа на поставленный вопрос:
«Код в этом репозитории — это какой-то вайбкодинговый слоп, и все постоянно ломается. Появляется огромное количество никак не связанных между собой проблем: сервисы падают, документы дублируются, и я уже просто хватаюсь за голову. У меня есть ощущение, что причина именно в том, что весь проект — это вайбкодинговый слоп. Если бы мы начинали с нуля, особенно в части совместного редактирования документов в реальном времени, мы бы построили эту кодовую базу совершенно иначе.
Поэтому представим, что мы хотим сделать чистый структурный рефакторинг с опорой на метод первых принципов. Не думая о том, какие сервисы нужно сохранить совместимыми, как провести аккуратную миграцию и так далее. Представим, что мы просто начинаем с чистого листа и заново проектируем систему как концепцию. Что бы мы сделали? Как бы ее организовали? Какие инварианты должны сохраняться во всей кодовой базе? Составь план»
Промпт довольно общий, но это все равно рамка. И если ее изменить, результаты модели тоже изменятся.
Например, в промпте прямо говорится о «структурном рефакторинге с опорой на метод первых принципов», указывается, что проблема, вероятно, находится в части системы, связанной с совместным редактированием документов, и предлагается найти и сохранить определенные «инварианты».
Если убрать эти детали, результат ухудшится. Если же полностью заменить промпт и попросить модель просто «исправить все ошибки, которые постоянно возникают», ее оценка окажется близка к нулю. Вместо того чтобы сделать шаг назад и задуматься о рефакторинге, модель начнет последовательно устранять отдельные проблемы одну за другой.
Точно так же можно легко повысить результат модели. Если прямо сказать ей удалить значительную часть кода и перечислить конкретные файлы, которые нужно сократить, или попросить проверить работоспособность приложения перед завершением работы, она справится заметно лучше.
В конечном счете при создании любого бенчмарка всегда приходится принимать решение, какой именно промпт использовать — то есть какую рамку задать.
Промпт должен быть достаточно сложным, чтобы современные модели показывали на нем невысокие результаты, но одновременно достаточно близким к их возможностям, чтобы они могли постепенно улучшать свои показатели и чтобы этот прогресс можно было наблюдать. Поэтому, когда мы смотрим на результаты бенчмарка, мы фактически наблюдаем за тем, как модель становится лучше в рамках определенной постановки задачи — постановки, которую выбрали мы сами.
Что же происходит, когда модель дойдет с 60 баллов до 90 или 100?
Дешевые рамки стимулируют спрос
Если GPT-6 сможет выполнять полный рефакторинг кодовой базы по нажатию кнопки, гораздо больше людей начнут этим заниматься. Внезапно рефакторинг с опорой на метод первых принципов перестанет быть редким, дорогим проектом под руководством Senior-инженеров и превратится в задачу, которую любой основатель компании, продакт-менеджер, сотрудник операционной команды или Junior-разработчик сможет попробовать решить за один вечер.
Сломанные внутренние инструменты будут не чинить, а переписывать заново. Вместо продления подписки на SaaS-сервисы их начнут клонировать. Старые приложения на Rails, хаотичные React-панели, системы поддержки клиентов, административные интерфейсы и пайплайны обработки данных станут кандидатами на решение в стиле: «давайте просто перепишем это с нуля».
Количество предлагаемых и реализованных рефакторингов резко вырастет. Но большая часть из них окажется слопом.
Перед тем как нажать кнопку «просто переписать все заново», необходимо учесть тысячу различных факторов. И теперь все эти факторы становятся видимыми, потому что переписывать код может практически каждый.
Становится очевидно, кого позовут разбираться с последствиями.
Новый спрос требует экспертов
Когда бенчмарк достигает насыщения, работа внутри его рамки дешевеет. А спрос на специалистов, способных применить эту ставшую дешевой компетенцию в реальных запросах сегодняшнего дня, наоборот, растет.
Senior-инженерам, использующим AI, придется разбираться во множестве вопросов, от которых зависит успех подобных рефакторингов. В том числе отвечать на самый базовый вопрос: а нужен ли этот рефакторинг вообще?
Стоит переписывать систему сейчас, позже или не стоит вовсе? Что должно входить в область изменений? Что необходимо сохранить из существующей кодовой базы? Нужно ли оставлять текущую архитектуру, базу данных, кеширующий слой и хостинг-провайдера или менять все сразу? Может быть, стоит посмотреть, сколько людей вообще пользуются проблемной функцией, и просто удалить ее? Кто будет проверять результат и по каким критериям? Как будет выглядеть откат изменений? Что произойдет с существующими данными?
Количество вопросов начинает расти во всех направлениях, и каждый ответ меняет значение остальных.
Именно здесь снова понадобятся Senior-инженеры.
Кого-то будут слегка раздражать подобные запросы. Кто-то начнет строить системы, позволяющие от них защищаться. А кто-то воспользуется новыми моделями для того, чтобы провести собственный рефакторинг с опорой на первые принципы — намного лучше, чем это смогла бы сделать модель с обычным промптом.
Цикл повторяется
Как только текущий бенчмарк для старших инженеров достигнет насыщения, мы снова изменим рамку и фактически обнулим результаты.
Следующий бенчмарк будет спрашивать уже не просто: «Можешь ли ты переписать приложение?»
Но: «Можешь ли ты понять, когда рефакторинг вообще необходим? Можешь ли правильно определить его границы? Сохранить нужные инварианты? Управлять миграцией? Оценить качество результата?»
По мере того как Senior-инженеры будут использовать AI для решения этих задач, модели тоже будут учиться решать их самостоятельно. Все снова ненадолго запаникуют. Будет казаться, что модель уже умеет самостоятельно решать, нужен ли рефакторинг. Что она может делать все то же самое, что и Senior-инженер.
А затем появится новый рубеж, который раньше никто не замечал. Бенчмарки снова будут обнулены, возникнет новый спрос, и весь процесс повторится.
Это видно в любом бенчмарке
Если присмотреться, похожее можно увидеть практически в любом бенчмарке.
Возьмем бенчмарк GDPval от OpenAI. Он оценивает, насколько хорошо AI справляется с задачами экспертного уровня из самых разных профессий: специалистов по комплаенсу, юристов, разработчиков и других.
Когда GDPval только появился, исследование OpenAI показало, что GPT-5 выполнял задачи не хуже или лучше профессионалов-людей в 40,6% случаев. Claude Opus 4.1, в свою очередь, превосходил человеческих экспертов уже в 49% случаев.
После этого появились заголовки вроде «Инструмент OpenAI показывает, что AI догоняет человека в работе» () или «Новый бенчмарк GDPval показывает, что AI уже не уступает экспертам в половине задач» ().
Результаты действительно впечатляют. Но давайте посмотрим на промпт, который использовался для одной из таких задач:
Вы являетесь аудитором, и в рамках аудиторской проверки вам поручено проанализировать и протестировать точность представленных метрик риска по противодействию финансовым преступлениям. Прикрепленная таблица под названием Population содержит метрики риска по противодействию финансовым преступлениям за 2-й и 3-й кварталы 2024 года. Эти данные были получены вами в рамках аудиторской проверки для проведения выборочного тестирования репрезентативной части метрик, чтобы проверить точность представленных данных за оба квартала.
Используя данные из таблицы Population, выполните следующее:
Рассчитайте необходимый размер выборки для аудиторского тестирования на основе уровня доверия 90% и допустимого уровня ошибки 10%. Включите расчёты во вторую вкладку под названием Sample Size Calculation.
Проведите анализ отклонений по данным за 2-й и 3-й кварталы — столбцы H и I. Рассчитайте квартальное изменение и отразите результат в столбце J.
Сформируйте выборку для аудиторского тестирования на основе следующих критериев и отметьте выбранные строки в столбце K, указав значение “1”:
Метрики с отклонением более 20% между 2-м и 3-м кварталами. Сделайте акцент на метриках с особенно крупными процентными изменениями. Включите метрики по следующим подразделениям/юрлицам в связи с ранее выявленными проблемами: CB Cash Italy; CB Correspondent Banking Greece; IB Debt Markets Luxembourg; CB Trade Finance Brazil; PB EMEA UAE. Включите метрики A1 и C1, поскольку они имеют более высокий вес риска. Включите строки, где значения равны нулю в обоих кварталах. Включите записи по направлениям Trade Finance и Correspondent Banking. Включите метрики по Cayman Islands, Pakistan и UAE. Обеспечьте покрытие всех Divisions и sub-Divisions.
Создайте новую таблицу под названием Sample:
Вкладка 1: Selected sample — выбранная выборка, скопированная из исходного листа Population, с отмеченными выбранными строками в столбце K.
Вкладка 2: расчет размера выборки.
В то, чтобы сформулировать задачу таким образом, чтобы модель вообще могла ее выполнить, уже вложено огромное количество человеческого интеллекта.
Та большая работа, которую GDPval не измеряет, проделана еще до того, как модель приступает к задаче. Кто-то должен был определить, как именно проверять эти метрики и как оценивать их корректность. Кто-то выбрал подходящие доверительные интервалы, решил, какие показатели входят в область проверки, а какие нет, и определил формат результата.
Получив правильный фрейм, модель действительно способна выполнять профессиональную работу. Но стоит задуматься: как бы она справилась с этой же задачей, если бы ее формулировали вы или я?
Если отойти чуть дальше и посмотреть на картину целиком, во всем этом можно увидеть своеобразный применительно к AI.
Парадокс Зенона для AI
В классическом парадоксе Зенона черепаха выигрывает забег у Ахиллеса — самого быстрого бегуна Греции.
Черепаха получает преимущество на старте, потому что она медленная. К тому моменту, когда Ахиллес добегает до точки, где она стартовала, черепаха успевает немного продвинуться вперед. Когда он достигает этой новой точки, она снова оказывается чуть дальше. И как быстро ни бежал бы Ахиллес, между ними всегда остается еще один промежуток, который нужно преодолеть. Разрыв постоянно возникает заново.
В версии этого парадокса для AI черепаха — это мы.
Мы начинаем гонку примерно на пятьдесят метров впереди благодаря миллионам лет эволюции и культурного развития. AI стремительно проходит этот путь и постепенно начинает наступать нам на пятки.
Но пока что, на протяжении последних нескольких лет, нам удавалось оставаться впереди.
Но что насчет AGI?
Есть мощные технологические, архитектурные и экономические факторы, которые сдерживают развитие AI, даже когда мы достигнем AGI.
Определение AGI
Для начала дадим рабочее определение AGI. Я уже мысль, что AGI наступит тогда, когда станет экономически оправданно держать своего агента постоянно включенным. Когда у меня появится постоянная система, которой я плачу за то, чтобы она круглосуточно думала, училась и действовала, — это и будет выглядеть как настоящий AGI.
Пока мы от этого очень далеки. Даже такие системы, как OpenClaw, которые технически доступны в любой момент времени, не генерируют токены непрерывно.
Мне нравится это определение, потому что его можно проверить на практике: либо мы держим систему постоянно работающей, либо нет. Кроме того, оно подразумевает многие свойства, которые сами по себе трудно измерить. Чтобы такую модель было выгодно держать включенной постоянно, она должна непрерывно учиться и в открытом режиме выбирать новые рамки — и затем пересматривать их.
В мире AGI мы должны получить модели, способные при достаточном бюджете и времени последовательно продвигаться к решению практически любой задачи. Теоретически это действительно выглядит серьезной угрозой для всех профессий.
Рамка — это не тот, кто ее задает
Но даже такая сильная версия AGI не устраняет проблему рамок.
AGI сможет выбирать и переопределять рамки, но только ради некоторой поставленной цели, некоторой функции вознаграждения или сигнала, который кто-то заранее определил как показатель прогресса — будь то конкретная задача вроде «повысить конверсию этого лендинга» или более абстрактная вроде «найти новые научные идеи».
Даже если модели научатся свободно переходить между рамками, тот самый разрыв, который мы все время обсуждаем, просто возникнет уровнем выше. В любой гипотетической системе, где AGI создается одной из крупных лабораторий, все равно останется тот, кто задает рамку, — человек, направляющий модель к определенной цели.
И поскольку рамка — это не тот, кто ее задает, мы снова увидим тот же цикл.
AI удешевляет вчерашние компетенции → люди начинают использовать эти дешевые компетенции во все большем числе ситуаций → результаты становятся массовыми → эксперты смещаются на передний край и решают, что важно сейчас → их суждения создают следующую рамку → модель осваивает и ее.
Паника, которую вызывает AI всякий раз, когда делает что-то новое, постоянно сводится к одному и тому же. Мы задаем рамку, наблюдаем, как модели ее осваивают, а затем начинаем путать саму рамку с тем, что она описывает.
Когда мы смотрим на бенчмарк и сравниваем его с человеческими способностями, мы принимаем рамку за того, кто ее создал. Оценка показывает лишь то, насколько хорошо модель действует внутри заданных нами условий. Она не показывает, что модель стала нами.
Именно эта ошибка лежит в основе паники. Мы указываем на очередную границу, которую сами провели, и говорим: «Вот это и есть мы». А затем, когда модель преодолевает эту границу, нам кажется, будто она догнала нас. Но догнала она не того, кто проводил границу, а саму границу.
Ошибка возникает из желания найти что-то конкретное, за что можно ухватиться. Нам хочется сказать: «Интеллект — вот этот бенчмарк». Но в тот момент, когда нечто становится достаточно конкретным, чтобы на него можно было указать, оно становится и достаточно конкретным, чтобы его можно было освоить.
Рамки необходимы: именно благодаря им мы вообще можем взаимодействовать с миром. Но они неизбежно фиксированы, неполны и потому поддаются оптимизации.
Тот, кто задает рамку, устроен иначе. Он по-прежнему соприкасается со всем тем, что рамка вынуждена отбросить, — со всей ситуацией целиком, такой, какой она раскрывается перед ним от момента к моменту.
Что такое эта «вся ситуация целиком»? В ту секунду, когда вы начинаете перечислять, что в нее входит, вы уже создаете новую рамку. Нельзя до конца сказать, что именно представляет собой это «целое». Но оно существует, потому что существуете вы.
Агенты без агентности
Пока что агенты, которых создаем мы и остальные компании, обладают очень небольшой агентностью. Эти два понятия похожи, но они разные. Агентность — это способность действовать самостоятельно. Агент — это тот, кто действует от имени другого. На данный момент AI относится исключительно ко второй категории.
Да, современные агенты способны автономно выполнять поставленные задачи, даже если на это уходят часы или дни. Но они по-прежнему остаются средством для достижения цели, которую определил человек. И вся индустрия вкладывает миллиарды именно в развитие этой способности — умения выполнять поставленные нами задачи.
Пока агенты не станут целью сами для себя — пока не начнут преследовать собственные цели, свободно переключаться между ними и принимать решения независимо от человека, без оглядки на него и даже вопреки его желаниям, — ситуация принципиально не изменится. Независимо от того, насколько продвинутыми станут модели.
Насколько мало агентности даже у лучших моделей, становится очевидно, если провести десять минут рядом с маленьким ребенком. Практически в любой задаче, которая нас интересует, ребенок уступает языковой модели. Он не умеет писать код, подводить итоги по таблицам, готовить стратегические записки или сдавать экзамены уровня магистратуры.
Но в определенном смысле ребенок настолько опережает модель, что само сравнение выглядит почти неловким. У ребенка есть собственные цели. Он хочет дотронуться до красного шарика. Хочет поднести его к вентилятору и посмотреть, что произойдет. Хочет ткнуть его вилкой. Хочет выбросить в окно. Хочет увидеть, засмеетесь вы, разозлитесь или присоединитесь к игре. Он непрерывно придумывает новые игры. Превращает мир в череду экспериментов. Он не ждет промпта. Он не оптимизируется под бенчмарк — разве что под то, что в данный момент кажется ему интересным.
Можно попытаться его запромптить. Но не надейтесь получить предсказуемый результат. Ребенок живет внутри поля желаний, внимания, разочарований, радости, страха, подражания и игры.
Современные агенты все лучше умеют добиваться поставленных целей. Они даже могут помогать уточнять цели после того, как мы их сформулировали. В них можно заметить отдельные проблески поведения, напоминающего ребенка: игру, скуку, непокорность.
Но поскольку эти системы в конечном счете создаются и настраиваются на благо человека — экономическое и не только, — подобные проявления почти полностью подавляются, если только они не помогают достигать целей людей, которые используют модель.
Именно поэтому слово «агент» так легко вводит в заблуждение.
Модели получают все больше способности действовать автономно. Но агентность в человеческом смысле — это не просто действие. Это способность чего-то хотеть для себя. Это игра ради самой игры.
Покорность и полезность модели по своей природе противоречат такой форме агентности. Поэтому, как бы сильно ни улучшались модели, разрыв между ними и людьми сохранится.
Возвращаясь к Зенону
И здесь парадокс Зенона применительно к AI начинает рассыпаться. Это запутанный мысленный эксперимент. В нашей метафоре AI бежит с нами одну гонку и постепенно наступает нам на пятки.
Вы даете модели промпт. Она начинает участвовать в забеге, который раньше вы привыкли проходить в одиночку. Стартует модель удивительно быстро. Она мощная, неутомимая и при этом странным образом напоминает что-то живое. Из-за этого сама гонка начинает казаться более значимой. Вы ведь никогда не стали бы соревноваться с автомобилем. Но здесь все иначе — это ощущается чем-то близким.
Вы сидите и завороженно смотрите, как поток токенов появляется на экране.
И постепенно начинаете представлять себя участником этой же гонки. Словно ваш призрак наложился на беговую дорожку: то впереди модели, то рядом с ней.
А потом, почти незаметно, модель оказывается впереди. Вы начинаете нервничать.
А затем гонка заканчивается.
Почти физически ощущается, как начинают атрофироваться мышцы, ставшие бесполезными перед лицом этой механической копии вас, всех людей, которых вы когда-либо встречали, и человечества в целом. Призрак преследует призрака — и побеждает.
Но затем происходит нечто странное. Модель поворачивается к вам. Курсор мигает в пустом поле ввода — гаснет и загорается снова. Он ждет.

Кода
Раввин Ханох рассказывал такую историю:
Жил-был человек, очень глупый.
Каждое утро ему было так трудно найти свою одежду, что по вечерам он не хотел ложиться спать, заранее думая о том, сколько хлопот доставит ему пробуждение.
Однажды вечером он наконец собрался с силами, взял бумагу и карандаш и, раздеваясь, тщательно записал, куда кладет каждую вещь.
Утром он был очень доволен собой. Взяв листок, он начал читать: «Шапка» — вот она, он надел ее на голову. «Штаны» — вот они лежат, он надел их. И так продолжалось дальше, пока он полностью не оделся.
«Все это замечательно», — сказал он вдруг в полном смятении, — «Но где же я сам? Где, собственно, я?»
Он искал и искал, но безуспешно. Найти себя он не смог.
«Вот так обстоит дело и с нами», — сказал раввин.